We’re excited to introduce our latest open-source project: Mailroom! It’s a flexible and extensible framework designed to simplify the creation, routing, and delivery of developer notifications based on events from platform systems (like Argo CD, GitHub/GitLab, etc.) In this post, we’ll share how Mailroom helps to streamline developer workflows by delivering concise, timely, and actionable notifications.
Crafting Delightful Notifications
On the Developer Experience team we believe strongly in the importance of timely, actionable, and concise notifications. Poorly crafted or overly spammy notifications can easily lead to frustration - nobody wants to have their focus disrupted by useless noise. Instead, we believe that the right notification at the right time can be incredibly powerful and even delightful, but only if done thoughtfully.
Notifications must be immediately useful, providing users with just the right amount of information they need to understand what is happening without overwhelming them. At SeatGeek, we carefully considered how to make notifications effective and meaningful, rather than intrusive or overwhelming.
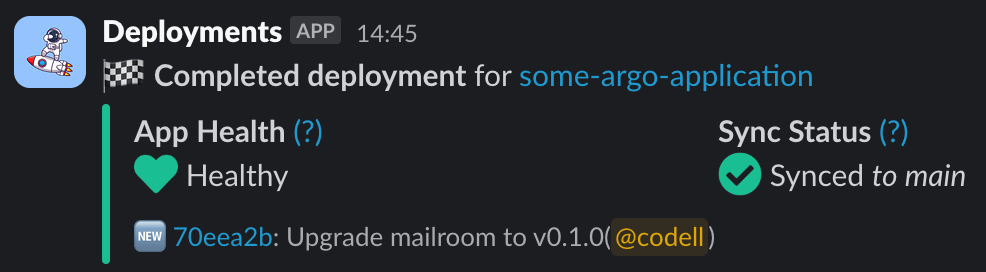
What was deployed? Was it successful? There’s not enough context here.
Sure, we could have gotten more clever with the templated JSON to include more information, but the basic template-based approach with a static recipient list would only take us so far. We wanted more control, like the ability to use complex logic for formatting, or sending different notifications to dynamic recipients custom-tailored to their role in the deployment (merger vs committer). This would enable us to provide a better experience like this:
The perfect amount of information! :chefkiss:
This requires creating custom notifications from scratch with code, being deliberate about what information we include, exclude, and how it gets presented. Our goal was to make 99% of notifications immediately useful without requiring further action from the user - if a notification disrupts or confuses rather than informs, it isn’t doing its job.
Why We Built Mailroom
The idea for Mailroom arose from a common pattern we observed. To build these delightful notifications, our Platform teams had a repeated need for specialized Slack bots to handle notifications from different external systems. Each bot basically did the same thing: transforming incoming webhooks into user-targeted notifications, looking up Slack IDs, and sending the messages. But building and maintaining separate bots meant setting up new repositories, implementing telemetry, managing CI/CD pipelines, and more. Creating new bots each time meant repeating a lot of boilerplate work.
Mailroom emerged from the desire to solve this once and for all. Instead of building standalone bots, we created a reusable framework that handles all the internal plumbing - allowing us to focus directly on delivering the value that our users craved.
With Mailroom, creating new notifications is straightforward. Developers simply define a Handler to transform incoming webhooks into Notification objects, and Mailroom takes care of the rest - from dispatching notifications to users based on their preferences, to managing retries, logging, and delivery failures.
How Mailroom’s Architecture Enables Platform Teams
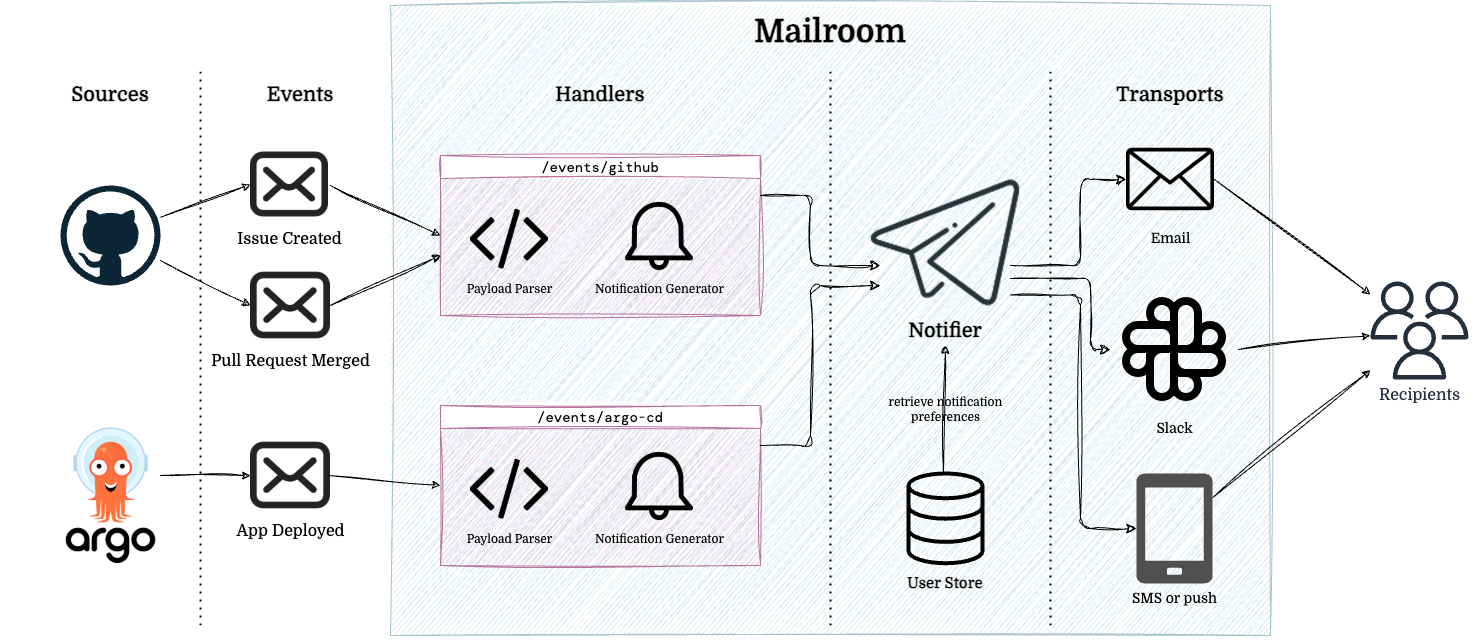
Mailroom provides all the scaffolding and plumbing needed - simply plug in your Handlers and Transports, and you’re ready to go.
Mailroom’s architecture
Handlers process incoming events, such as “PR created” or “deploy finished,” transforming them into actionable notifications.
Transports send the notifications to users over their preferred channels - whether that’s Slack, email, or carrier pigeon.
The core concepts are simple, yet powerful, enabling flexibility for whatever your notification needs are. Want to send a GitHub PR notification via email and a failed deployment via Slack? Just write your Handler and let Mailroom’s Notifier do the rest!
By making it easy for developers to craft custom notifications, Mailroom helps our Platform team iterate quickly, ensuring that notifications remain targeted, relevant, and useful. By removing the boilerplate work, developers can focus on delivering real value without worrying about the underlying infrastructure.
Open Sourcing Mailroom
Today, we are announcing the availability of Mailroom as an open-source project to help other teams who face similar challenges with internal notifications. Whether you’re looking to build a quick Slack bot or need a scalable notification system across multiple services, Mailroom has you covered.
Mailroom allows Platform teams to focus on what really matters: delivering valuable information to users at the right time and in the right format - without needing to build out the underlying plumbing. We’ve provided some built-in integrations to help you get started faster, including Slack as a transport and both in-memory and PostgreSQL options for user stores. And we’re looking forward to expanding Mailroom’s capabilities with new features like native CloudEvents support in upcoming versions.
Get Started
Getting started with Mailroom is easy! You can find all the information in our GitHub repository. There’s a Getting Started guide that helps you set up a basic project using Mailroom, as well as more in-depth documentation for core concepts and advanced topics.
We welcome contributions from the community! Feel free to open issues, suggest features, or submit pull requests to help make Mailroom even better.
Continuous Integration (CI) pipelines are one of the foundations of a good developer experience. At SeatGeek, we’ve leaned heavily on CI to keep developers productive and shipping code safely.
Earlier this year, we made a big push to modernize our stack by moving from using Nomad for orchestration to using Kubernetes to orchestrate all of our workloads across SeatGeek. When we started migrating our workloads to Kubernetes, we saw the perfect opportunity to reimagine how our CI runners worked. This post dives into our journey of modernizing CI at SeatGeek: the problems we faced, the architecture we landed on, and how we navigated the migration for 600+ repositories without slowing down development.
A Bit of History: From Nomad to Kubernetes
For years, we used Nomad to orchestrate runners at SeatGeek. We used fixed scaling to run ~80 hosts on weekdays and ~10 hosts on weekends. Each host would run one job at a time, so hosts were either running a job or waiting on a job.
This architecture got the job done but not without its quirks. Over time, we started to really feel some pain points in our CI setup:
Wasted Resources (and Money): Idle runners sat around, waiting for work, not adjusting to demand in real-time.
Long Queue Times: During peak working hours, developers waited… and sometimes waited a bit more. Productivity suffered.
State Pollution: Jobs stepped on each other’s toes, corrupting shared resources, and generally causing instability.
We decided to address these pain points head-on. What we wanted was simple: a CI architecture that was fast, efficient, and resilient. We needed a platform that could keep up with our engineering needs as we scaled.
New Architecture: Kubernetes-Powered Runners
After evaluating a few options, we landed on using the GitLab Kubernetes Executor to dynamically spin up ephemeral pods for each CI job. Here’s how it works at a high level:
Each CI job gets its own pod, with containers for:
Build: Runs the job script.
Helper: Handles git operations, caching, and artifacts.
Svc-x: Any service containers defined in the CI config (eg databases, queues, etc).
Using ephemeral pods eliminated resource waste and state pollution issues in one fell swoop. When a job is done, the pod is gone, taking any misconfigurations or leftover junk with it.
To set this up, we leaned on Terraform and the gitlab-runner Helm chart. These tools made it straightforward to configure our runners, permissions, cache buckets, and everything else needed to manage the system.
Breaking Up with the Docker Daemon
Historically, our CI relied heavily on the host’s Docker daemon via docker compose to spin up services for tests. While convenient for users, jobs sometimes poisoned hosts by failing to clean up after themselves, or they modified shared Docker configs in ways that broke subsequent pipelines running on that host.
Another big problem here was wasted resources and a lack of control of those resources. If a docker compose file spun up multiple containers, they would all share the same resource pool (the host).
Kubernetes gave us the perfect opportunity to cut ties with the Docker daemon. Instead, we fully embraced GitLab Services, which allowed us to define service containers in CI jobs, all managed by Kubernetes, with their resources defined according to the jobs individual needs. And another upside was that GitLab Services worked seamlessly across both Nomad and Kubernetes, letting us migrate in parallel to the larger Kubernetes runner migration.
The Migration Playbook: Moving 600+ Repos Without Chaos
Migrating CI runners is a high-stakes operation. Do it wrong, and you risk breaking pipelines across the company. Here’s the phased approach we took to keep the risks manageable:
Start Small
We began with a few repositories owned by our team, tagging pipelines to use the new Kubernetes runners while continuing to operate the old Nomad runners. This let us iron out issues in a controlled environment.
Expand to Platform-Owned Repos
Next, we migrated all repos owned by the Platform team. This phase surfaced edge cases and gave us confidence in the runner architecture and performance.
Shared Jobs Migration
Then we updated shared jobs (like linting and deployment steps) to use the new runners. This phase alone shifted a significant portion of CI workloads to Kubernetes (saving a ton of money in the process).
Mass Migration with Automation
Finally, using multi-gitter, we generated migration MRs to update CI tags across hundreds of repositories. Successful pipelines were merged after a few basic safety checks, while failing pipelines flagged teams for manual intervention.
Was it easy? No. Migrating 600+ repositories across dozens of teams was a bit like rebuilding a plane while it’s in the air. We automated where we could but still had to dig in and fix edge cases manually.
Some of the issues we encountered were:
The usual hardcoded items that needed to be updated, things like ingress urls and other CI dependent services
We ran into a ton of false positives grokking for docker compose usage in CI, since it was often nested in underlying scripts
Images built on the fly using docker compose had to instead be pushed/tagged in a new step, while also needing to be rewritten to be compatible as a CI job entrypoint
We also set up shorter lifecycle policies for these CI-specific images to avoid ballooning costs
Some pods were OOMing now that we had more granular request/limits, this needed to be tuned for each job’s needs above our default resourcing
We also took this as a chance to refactor how we auth to AWS, in order to use more granular permissions, the downside was that we had to manually update each job that relies on IAM roles
What About Building Container Images?
One of the thorniest challenges was handling Docker image builds in Kubernetes. Our old approach relied heavily on the Docker daemon, which obviously doesn’t translate well to a Kubernetes-native model. Solving this was a significant project on its own, so much so that we’re dedicating an entire blog post to it.
Closing Thoughts: A Better CI for a Better Dev Experience
This has measurably increased velocity while bringing costs down significantly (we’ll talk more about cost optimization in the third post in this series).
Through this we’ve doubled the number of concurrent jobs we’re running
and reduced the average job queue time from 16 seconds down to 2 seconds and the p98 queue time from over 3 minutes to less than 4 seconds!
Modernizing CI runners wasn’t just about cutting costs or improving queue times (though those were nice bonuses). It was about building a system that scaled with our engineering needs, reduced toil, increased velocity, and made CI pipelines something developers could trust and rely on.
If your team is looking to overhaul its CI system, we hope this series of posts can provide ideas and learnings to guide you on your journey. Have fun!
At SeatGeek, we believe security isn’t just the responsibility of a dedicated team – it’s something we all own. As part of our ongoing efforts to build a strong security culture, we’ve dedicated the month of October to educating, engaging, and empowering our entire company around key security concepts. This effort, which we’ve dubbed “Hacktober,” is all about scaling security awareness in a way that reaches everyone, from engineers to business teams, no matter their location.
Why Security Awareness Matters
We say this constantly, but it’s always worth repeating: security is everyone’s problem. The challenge is that while security covers a huge range of topics, we have limited time and relatively small teams to handle it all.
Security threats, specifically cybersecurity threats, continue to evolve and attackers often target the weakest links. Educating everyone about the fundamentals of security not only reduces risks but also empowers individuals to make smarter decisions. Whether it’s spotting phishing attempts or securing personal devices, awareness is the first line of defense. Security Awareness Month is our chance to drive this message home and foster a proactive security mindset across all teams.
Hacktober Events
SeatGeek is a globally-diverse and remote-friendly company, so when coming up with live events to host throughout the month, we had to keep that in mind. Overall, the categories of events and materials we decided to invest in during Hacktober were Presentations, Published Media, and Hands-on Activities.
By taking a Show & Tell approach to most of our presentations, we were able to make some informative and entertaining feature dives and demonstrations of our tooling and detection & response processes. Some of the exciting topics this month included a deep dive into Malware Alert Response, How We Do DevSecOps at SeatGeek, and a closer look at Kubernetes and Cloud Security.
A big focus of the majority of published media we’re sending out is all about Phishing, Smishing, Vishing, and whatever other kind of ishings are out now (Gen-AI-ishing?). While we do regular training and testing for phishing, it’s often a topic that can benefit from different approaches. For Hacktober, we created an engaging live-action video on phishing and, spoiler alert, we’ll be running a phishing fire drill later this month 🤫.
And not to say we saved the best for last, but this was one that a lot of us were most excited for: we held a Security Capture the Flag event that saw a better-than-expected turnout from across the company! 🙌🎌
We tend to notice that more folks engage with Security Capture the Flag events – where they can learn about security topics through puzzles and challenges – than other event types. We have challenges that span many different categories including Web and API security, Cloud Security, Network, Forensics, Cryptography, Reverse Engineering, and more! By including trivia, basic forensics, and OSINT challenges, we were also able to make the event fully inclusive for the entire company, not just engineers!
A Focus on Shifting Left
One reason we want to increase security awareness across the company is to drive the company to Shift Left. At a high level, this has been the primary focus of all of Hacktober!
The idea, or strategy, of “Shift Left” is to integrate security practices as early as possible into the software development lifecycle (SDLC). The goal is to prevent vulnerabilities from being introduced early in the process so that they don’t become issues later.
While shifting left is part of our larger goal, we don’t see it as just a box to check or a series of milestones. Instead, we’re embracing it as part of SeatGeek’s normal engineering culture. Automation, self-service, ease-of-use, and ultimately, meeting scalability requirements are all driving forces that not only enable us to work towards this idea for the company, but aligns our entire engineering department with it as well!
Conclusion
Security is an ever-evolving challenge, but it’s one we face together as a company. By embedding security into our daily processes, embracing automation, and tapping into community-driven efforts like bug bounty programs, we’re able to scale both our knowledge and defenses. Hacktober is just one chapter of many in our journey at SeatGeek, but it’s an essential step in building a security-first mindset. We encourage you to prioritize security in everything you do too!
At SeatGeek, we manage our infrastructure with Terraform, and as part of the Developer Experience team, we’re always looking for ways to help our product teams iterate on infrastructure within their own repositories—whether it’s setting up AWS resources, configuring alerts, or spinning up a new repository. Our goal is to provide golden paths that simplify these tasks.
We know not every engineer is familiar with Terraform, and that’s why we focus on creating these golden paths: to standardize the process and lower the barrier to entry. This way, teams can get started with Terraform quickly and confidently.
To further support this effort, we’re excited to introduce two open-source packages: @seatgeek/node-hcl (Github, npm) and a Backstage plugin for HCL scaffolder actions (Github, npm), designed to make working with Terraform even easier.
🙅 The Problem: Terraform + Node.js + Backstage
The challenge we faced was finding a way to simplify the process of bootstrapping new Terraform code across our repositories, many of which already had Terraform set up. We already rely on Backstage to create software templates for Terraform, but this only worked well in the context of greenfield repositories. For repositories with existing Terraform configurations, things became a bit more complicated.
Out of the box, Backstage’s built-in fetch:plain and fetch:template actions either create new files or fully overwrite existing ones—a basically all-or-nothing approach. This presents a challenge with shared files in the root Terraform directory like provider.tf, state.tf, main.tf, variables.tf, and output.tf, which may not always be present. And when they are, overwriting them adds extra work for engineers, who then have to manually reconcile these changes–adding more engineering toil in a solution aiming to reduce it.
Since Backstage is built on Node.js, we are limited to the plugins and libraries available within that ecosystem. Initially, it appeared that existing Node.js tools could help us handle HCL. Libraries such as @cdktf/hcl2json (based on @tccmombs/hcl2json) allowed us to convert HCL to JSON, which seemed promising as the first step towards manipulating the data. Then by leveraging open-source Backstage plugins, such as Roadie’s scaffolder actions for working with JSON directly, we could have addressed part of the issue. However, without a way to convert the JSON back into HCL, this would be a partial, incomplete solution at best.
And unfortunately, converting JSON back to HCL isn’t as straightforward as it sounds. As noted in this post by Martin Atkins, while HCL can be parsed into JSON for certain use cases, it’s not without its limitations, particularly with Terraform HCL:
A tool to convert from JSON syntax to native [HCL] syntax is possible in principle, but in order to produce a valid result it is not sufficient to map directly from the JSON infoset to the native syntax infoset. Instead, the tool must map from JSON infoset to the application-specific infoset, and then back from there to the native syntax infoset. In other words, such a tool would need to be application-specific.
In other words, while it’s technically possible to convert JSON back into the native HCL format, the conversion would need to understand the specific structure and nuances of Terraform’s flavor of HCL. Otherwise, you’d end up with valid HCL syntax that isn’t valid Terraform.
This meant the only viable path was to work directly with HCL for both reading and writing—but there was no Node.js-based solution for doing exactly that as Hashicorps HCL spec is only available in Go.
That’s where we found a solution in Go’s WebAssembly port.
🔥 The Solution: Go + WebAssembly + Backstage
After exploring different options and observing how tools like HashiCorp’s terraform-cdk utilized Go-based solutions to handle converting HCL to JSON and formatting HCL in Node.js, we decided to also build on top of Golang’s WebAssembly (Wasm) capabilities. Golang’s WebAssembly port allows Go code to be compiled and run on the web, enabling JavaScript engines like Node.js to take advantage of the Go ecosystem. By leveraging this technology, we were able to write the functions we needed for merging HCL files directly in our Backstage plugins.
Here’s a quick breakdown of how we integrated Go’s WebAssembly with Node.js in our Backstage plugin to handle HCL file operations like merging:
Building @seatgeek/node-hcl
We developed @seatgeek/node-hcl to leverage Golang’s WebAssembly port as the first piece that will allow us to bridge the gap between Backstage’s Node.js-based ecosystem and the HCL world of Terraform. This package allows us to write the functions we need in Go for working directly with HCL and later export these functions as Javascript.
1. Defining the implementation: (source) We first define the Go function we need to expose, such as a Merge function that combines two HCL strings using the hclwrite package from HashiCorp’s HCL library.
2. Registering the Javascript bindings: (source) Once the Go function is defined, it is registered and made callable within JavaScript through WebAssembly. This process involves mapping the Merge function to a JavaScript-compatible format.
3. Compiling Go to Webassembly: (source, source) The final code is then compiled to WebAssembly by targeting GOOS=js GOARCH=wasm. This creates a main.wasm file that is then gzipped and packaged. Since we want to also have this executable in a browser, the Javascript support file is packaged alongside the compiled wasm.
4. Exporting the bindings as Javascript: (source, source) Both the compiled wasm and the Javascript support file are loaded, allowing us to wrap the WebAssembly bindings in a JavaScript function that can be imported and used within any Node.js project.
Integrating into Backstage
The last piece for putting it all together was to create a Backstage plugin that could make use of our new package. We developed @seatgeek/backstage-plugin-scaffolder-backend-module-hcl for this purpose. It provides custom scaffolder actions to read, merge, and write HCL files through Backstage software templates.
From this point, all we had to do is:
1. Import the library: Include the published @seatgeek/node-hcl package into our new Backstage plugin.
2. Register the actions: (source, source) Develop the custom scaffolder actions using Backstage’s plugin system. These actions will use the merge function we exported earlier.
3. Import the plugin: Include the published @seatgeek/backstage-plugin-scaffolder-backend-module-hcl plugin to our internal Backstage instance at packages/backend/src/index.ts.
4. Reference the actions in a software template: Then with all the pieces together, anyone can just include the actions in their software templates like so:
At SeatGeek, we strongly believe in the value of open source. Solving this problem wasn’t just a win for our team—it’s something we knew could help other teams in similar situations. By open-sourcing @seatgeek/node-hcl and our Backstage plugin for HCL scaffolder actions, we’re contributing back to the community that has helped us build amazing solutions. Whether you’re using Terraform, managing Backstage software templates, or simply want to work with HCL in Node.js, we hope these tools will make your life a little easier.
Both libraries are available on our GitHub. Contributions, feedback, and issues are welcome. We hope these tools can serve as a starting point or a valuable addition to your developer workflows.
At SeatGeek, the Fan Experience Foundation team recently upgraded from React 17 to 18, and we’d like to share some of the processes we followed to make this upgrade possible on a large-scale React codebase.
Before diving deeper, some context on the codebase we are upgrading is necessary. SeatGeek has been moving its React application over to the NextJS web framework for some time now. This means that we have two React applications in our codebase, both working together to serve seatgeek.com. Thus, throughout this article we will refer to the two applications as sg-root and sg-next to differentiate between the various problems we will cover. Further, we write our frontends in TypeScript, and our unit tests in Jest, so we expect to have no errors when we are finished. With this knowledge in hand, let’s begin the upgrade.
Getting Started
Most reading this are likely already aware that React has published an upgrade guide for version 18. However, when working on a large scale React application, you cannot simply upgrade your react and type dependencies, and call it a day. There will be many workarounds, compromises, and fixes that will need to be applied to make your application functional. While React 18 itself has few breaking changes, our complex configuration of dependencies, both old and new, can lead to some difficult hurdles. Before following the upgrade guide, we recommend thinking hard about what your upgrade plan is. Write down any known unknowns before you begin. Below are some of the questions we wrote down, before beginning on this journey.
How does React recommend upgrading to version 18?
We were fortunate the documentation for React was written so clearly. After reading the upgrade guide, it became obvious that we didn’t have to subscribe to every new feature, and that much of an existing application would be backwards compatible. Perhaps the new React beta docs could take a note from how NextJS is gathering community feedback in their documentation. For example, we would love to see compatibility tables for widely used react packages, such as react-redux in a future upgrade guide.
How does the open source community handle upgrades to 18?
While some react packages communicated their compatibility with React 18 well, we found others such as @testing-library/react to be lacking in comparison. The more digging we had to do into obscure Github issues and StackOverflow posts, the worse the experience became. With that said, the majority of communities made this process easy for us, and that says a lot for how far the JavaScript community has come.
Are any of our dependencies incompatible with 18?
When this project began, we didn’t come across any dependencies that did not have support for React 18. Unfortunately, we later discovered that we still had tests that relied on enzyme in legacy corners of the application. It turned out that enzyme did not even officially support React 17, so this would become one of the more inconvenient problems to deal with.
Which new features will we immediately be taking advantage?
While we did not have any immediate plans to use some of the new React hooks, we did intend on integrating the new server rendering APIs, as well as the updates to client-side rendering, such as replacing render with createRoot.
Answering these questions helped us understand the high-level problems we would face. With some initial research out of the way, we began following the official upgrade guide.
Dependency Upgrades and Hurdles
Throughout the upgrade, many dependencies were updated for compatibility, in other cases it was done to fix a bug. We started by upgrading what you’d expect, react itself in sg-root. For sg-next react is only a peerDependency of the project, so only the types had to be added.
After react 18 was finished installing, we took a look at some of the react dependencies we used with webpack and NextJS, to see if any of them could be removed or upgraded. Since @hot-loader/react-dom had no plans of supporting React 18, we removed it from the sg-root project. Developers could continue to use fast refresh through NextJS in the sg-next project.
Next we attempted to compile the application. An error was thrown that complained about multiple versions of React. We ran yarn why react, and noticed that we had an older version of @typeform/embed that relied on React 17.
Fortunately, we use yarn at SeatGeek, so we were able to take advantage of yarn’s selective dependency resolutions feature to workaround scenarios where our dependencies were not yet supporting React 18. While this could be problematic in special cases, it worked perfectly for our needs. If you are struggling with an older dependency that relies on React 17 or lower, during the upgrade, we highly recommend this approach if you happen to be using yarn already. It’s worth keeping in mind however, that forcing a version of react to resolve for all dependencies, is not the correct approach when those dependencies are incompatible with the new version of React. After adding react to the resolutions, and running yarn, our yarn.lock was recreated, and the error went away.
At this point the application was compiling successfully. We were able to see the first runtime errors as soon as any page loaded. The first runtime error came from the react package 😲.
The stack trace for this error didn’t provide any obvious culprits and searching for similar issues online returned many results. Each one, tended to arrive at a completely different solution. After reading plenty of Github discussions, we came across a merge request in a public repository. While the error was not identical, the developer was upgrading styled-components in hopes to achieve compatibility with React 18. Sure enough, upgrading styled-components to v5.3.6 resolved the issue. While we don’t know which commit was responsible, we know it must be one of the ones shown here.
With that fixed, yet another error was thrown.
Researching this error quickly landed us on the following StackOverflow post. Which made sense, since we were still running react-redux v7, and v8 added support for React 18. After removing the @types/react-redux package (since types are now built-in), and upgrading react-redux to v8, the error disappeared.
Here is a final list of dependencies that were modified to complete this upgrade.
Application Changes
After reading over the Upgrade Guide, it became clear that we would have to update both our usage of Server Rendering APIs in sg-root, as well as the Client Rendering APIs in sg-root and sg-next. While this is a fairly straightforward find and replace, it’s important to do this methodically, and make sure you don’t miss any files in such a large project. This is especially important since many of the older APIs were deprecated, and not removed. Your application will continue to compile, but receive runtime errors and warnings when used in the wrong way.
Something worth calling out in the guide, about the new render method:
We’ve removed the callback from render, since it usually does not have the expected result when using Suspense
While the AppWithCallbackAfterRender example provided by the documentation may work for some, we found this example from Sebastian Markbåge to work for our needs. Below is a more complete version of it, for convenience. But as they also mention in the guide, the right solution depends on your use case.
If you aren’t already using StrictMode, now is probably a good time to start. While it wasn’t widely used in our repository, it would have made upgrading much easier. NextJS strongly recommends it, and offers a simple configuration flag for enabling it app-wide. We will likely adopt an incremental strategy in the future, to introduce it to our codebase.
At SeatGeek, most of our applicable react code lives in .ts and .tsx files, some of the older legacy code is in .php files. It is possible we may have missed the legacy code if we were moving too fast, so it’s a good idea to take it slow, and be thorough when working on a large project. Lastly, make sure to update any forms of documentation throughout your codebase, and leave comments where possible to provide context. You will find this makes subsequent upgrades significantly easier.
Deprecations and Breaking Changes
One of the bigger breaking changes in React 18, is the removal of Internet Explorer support. While this didn’t directly impact our upgrade process at SeatGeek, it is worth calling out as something to consider. As we were supporting Internet Explorer on our site not long ago. If your clients need to support IE, sticking with 17 or lower is your only choice. Although with IE 11 support from Microsoft ending last year in ‘22, you should probably look to change which browsers your clients are using.
An issue we did experience however, can be found in the Other Breaking Changes section of the upgrade guide, called “Consistent useEffect timing”. This change caused certain functionality throughout our application to stop working as expected. Mostly this was relegated to DOM events, such as keypresses and clicks. While each case was unique, the broader issue here has to do with timing as React says. You’ll find that after identifying and fixing a few of these issues, that your application was really just relying on the unpredictable behavior in React 16 & 17.
Type Checking
At SeatGeek our frontend applications are written in TypeScript, a superset of JavaScript that adds optional static typing. To upgrade to React 18 successfully, the TypeScript compiler would need to report that we had no type errors. By upgrading our @types/react and @types/react-dom dependencies we would begin to see what type errors we would have to resolve.
Children Prop
One of the biggest TypeScript definition changes in 18, is that React now requires the children prop to be explicitly listed when defining props. Let’s say we have a dropdown component, with an open prop, and we would pass children to render as menu items. The following example explains how the type definitions would need to change to support React 18.
Code Mod
TypeScript will not compile a React 18 application, until these errors are resolved. Fortunately the React documentation recommends using a popular open source code mod to resolve these errors. The mod covers the conversion of implicit children props to explicit, as well as a handful of other scenarios. This process was not without issues however, and did require us to go back in and manually fix areas of the codebase where the code mod created either invalid code, or incorrect types. For this reason, each transform was ran individually, and only valid changes were committed.
Circular JSON
After all code mod transforms had run, and some minor manual fixes were made, we ran the TypeScript compiler. The terminal displayed the following unhelpful type error, with no additional context.
After some debugging and research into this error, we were led to the following chain of Github issues and pull requests
The fix for diagnostic serialization sounded promising, so we began upgrading TypeScript one minor version at a time. We found TypeScript v4.6 got rid of the type error and produced useful compiler output. We chose not to upgrade TS further, since we wanted to keep the amount of unnecessary change to a minimum. Now when we ran tsc , we received the following output.
TS Migrate
While some of the errors were unique to the TypeScript v4.6 upgrade, others were due to type errors the code mod was unable to resolve for us. We focused on fixing the React specific errors, and chose to suppress the rest of the errors using airbnb’s ts-migrate. This tool is extremely helpful in making it easier to fix type errors over time, especially if you are working on a large codebase that was not originally written in TypeScript. We chose to prioritize the suppressed type errors at a later date, and move on. With TypeScript reporting zero type errors when we ran tsc, we were able to proceed to the next challenge in upgrading React.
Testing
For any large enterprise product with a lot of tests, you’ll likely find this to be where you spend most of your time upgrading a core dependency of your project. Seatgeek.com has 4,601 tests in sg-root and 3,076 tests in sg-next (not including end-to-end tests), at the time of writing. Some of these tests rely on newer practices, such as those in the popular @testing-library/react package. Others are legacy tests, that rely on the now defunct enzyme package. As you can imagine, getting all of these tests passing would require tackling some unique problems.
React Testing Library
Unsurprisingly, after upgrading React, you also need to make some changes to your core testing utility belt. If you were writing tests for React Hooks, you’ll have to remove @testing-library/react-hooks as renderHook is now part of the testing library.
You can start with replacing the import statements.
Then you will have to rework some of your tests. Several of the changes you’ll need to make to support the new method of react hook testing are mentioned here. Even after these changes, you will likely need to make many more tweaks to your tests, so we recommend taking your time with this transition, and committing often.
Warning: An update to Component inside a test was not wrapped in act(…)
You will likely see this log often, sometimes it is even a helpful warning. The majority of the time, however, during this upgrade it was a red-herring. No matter howmanyarticles, and Github issues we read on the topic, we tended to find our own solution to the problem. Sometimes the issue had to do with our Jest configuration, how mocks were setup in the test file, or even how Jest Timer functions were used. In a few cases we even ended up having to wrap fireEvent in testing libraries act API, which should not have been necessary.
We found it to be much more difficult than we would have liked to get the test suite that used @testing-library/react up to date. It was like pulling teeth, due to the complex changes to how React 18 behaves with the addition of the IS_REACT_ACT_ENVIRONMENT global (more on this below), and many of the underlying API changes to react testing library. If your test code isn’t up to the highest standards of quality, you may find this challenge daunting at first, and it may best to distribute the effort involved. My last bit of advice here would be to read carefully both of the documentation, and this blog post. Worst case scenario, you’ll find yourself reading dozens of 100+ comment Github issues, but hopefully it doesn’t come to that.
Enzyme
Working around issues with Enzyme on React 18 was not easy, especially because Enzyme is dead. Not only is it missing official support for React 17, but according to the developer who dragged it through the mud to run on 17, we were not going to get support of any kind for 18.
While many of these problems you’ll have to deal with on a case by case basis, you will still need some partial support for React 18 to avoid having to remove Enzyme from hundreds or thousands of test files. My recommendation would be to fork enzyme-adapter-react-17 as was done here, and you’ll find many of your tests passing as a result.
Ultimately though, you’ll need to replace a few of the more problematic tests with @testing-library/react and reconfigure the “React Act Environment” as described below. Then begin the process of paying down your technical debt with enzyme before they release React 19.
React Act Environment
In React 18, we saw the proposal and introduction of global.IS_REACT_ACT_ENVIRONMENT. This allows us to communicate to React that it is running in a unit test-like environment. As React says in their documentation, testing libraries will configure this for you. Yet you should be aware that this comes with much to manage yourself, depending on the test.
For that reason, we added the following utility methods, which make it easier to manage whether this new flag is set.
In an ideal world, this would be unnecessary, and we imagine over time tools such as this, will move out of our code, and into the testing library itself. Until it is inevitably made obsolete.
Window Location
Prior to upgrading, we relied on Jest 23, which used an older version of JSDOM. This meant we could use the Proxy API to intercept, and occasionally redefine properties of an object. This was especially useful for globals, such as window.location that were sprinkled all across the application. Over the years, you’d find developers changing the location of the current page in many different ways.
For example
window.location = url;
window.location.href = url;
Object.assign(window.location, { href: url });
window.location.assign(url);
etc
Proxies could easily intercept all of these attempts to change the object, and allow our test framework to assert properties that were changing on the global location object. Yet in newer version of Jest, Proxying was no longer possible on global objects. Instead you get all sorts of runtime TypeErrors, that can be difficult to debug, or find the source of.
Since this was a fairly common issue that had been around since JSDOM 11, we would need a general solution that could be applied to any of our tests, and require minimal changes. In order to continue to support our test suite, we introduced a small test helper, and got rid of the old Proxying logic. This helper could be used on a case by case basis, and mocks the window location, rather than intercepting its mutations.
Then we can call this helper function before our tests run, and properly test window.location changes once again.
Silence Warnings
In some of the older legacy tests that relied on enzyme, we found React calling console.error. This resulted in several failing test suites. Below is an example of the reported error message.
To workaround this, we added a small utility that can be used on a case by case basis to avoid React’s complaints, allowing the tests to continue as they would normally uninterrupted. Generally, you wouldn’t want to silence calls to console.error. However, in the case of these tests, it was safe to ignore them. You can find the utility to suppress these error messages below.
Error Boundary
In some circumstances, you might find asserting that an error occurred, is more difficult than it should be in Jest. In these cases, consider leveraging React’s ErrorBoundary components. If you have a component that you want to assert is showing a fallback when failing, you can use @testing-library/react to wrap your component in an <ErrorBoundary fallback={jest.fn()}> and expect your mock function to be called. See the example below for more on how this works in practice.
Bugfixes
After thorough review and months of QA, several bugs were identified throughout our application. The bugs were logged, researched, and fixed. Then new rounds of QA occurred, until we felt confident that this upgrade wasn’t going to break any critical functionality. Below is an overview of a few of the bugs we ran into while upgrading to React 18.
Click Events
Throughout our website we have many different components that rely on click events that occur outside of an HTML element. Such as dropdown, modals, popovers, and more. After upgrading to React 18, most of these components appeared not to render at all. This was because the trigger to open these components, often fired a click event, that would cause them to immediately close. This is the “Consistent useEffect timing” problem we described earlier that React wrote about in their documentation on Breaking Changes. After a little digging into the React repository issues, we came across this issue that described the problem well.
in React 18, the effects resulted from onClick are flushed synchronously.
One possible workaround is to delay the subscription with a zero timeout.
Given the advice, we went ahead and tried wrapping our window.addEventListener calls in setTimeout and our components began behaving as we might expect them to once more. It’s worth mentioning, that this issue can also be fixed by calling stopPropagation on the triggering elements, but this might be untenable depending on how large your codebase is.
You can see this issue in more detail in the sandbox below
Search Rendering
The seatgeek.com website includes a lot of search functionality to make it easy for our users to find tickets to the latest events. While testing React 18, we noticed an almost imperceptible flash of our search results dropdown on screen as the page was loading. This was after months of QA, and no one had reported any issue like this. So we were not sure if it was possible we were just seeing things. In order to verify this, we opened the developer tools and clicked on the performance tab. We enabled the screenshots feature, and then clicked record and refresh. The results proved that we were not in fact going mad, but that the dropdown was appearing on the page, albeit only for 100ms.
To make this easier to experience, below you can find a reproduction sandbox of the issue. These sandboxes are best viewed in their own window, since you’ll need to use the developer tools as we described above, or refresh the page a few times at the very least.
After reviewing the example code, we are sure a few readers will be wondering why we aren’t just using the autoFocus attribute, and calling it a day. In our application, our search component is used in dozens of places all over the application. This means we have cases where we not only need to manage the focus, but need to modify the DOM based on whether or not the input is focused. In other words, we often need to implement controlled components, over uncontrolled ones.
In the past, Safari appears to have had issues with this, and so someone decided to fix that bug. The solution to the Safari issue, at the time, appears to be to use a Promise.resolve and defer focus. However, this problematic code lead to the issues we now see in React 18. If you remove the Promise, you’ll find the issue disappears. Because timing was important, we knew the problem was likely related to the addition of automatic batching in React 18.
With automatic batching in mind, if we wrap the call to focus and setFocused in a flushSync instead of removing the promise, we will also find this fixes the issue. However, this feature can hurt the performance of your application, so you may want to use it infrequently if you must.
Ultimately, the fix for this issue was fairly uninteresting, and we were able to avoid the addition of flushSync, and removing the Safari patch, by just adding more state, and skipping unnecessary state updates at the proper time. This will depend on your use case however, so we felt it was important to review some of the alternatives that may work in this circumstance.
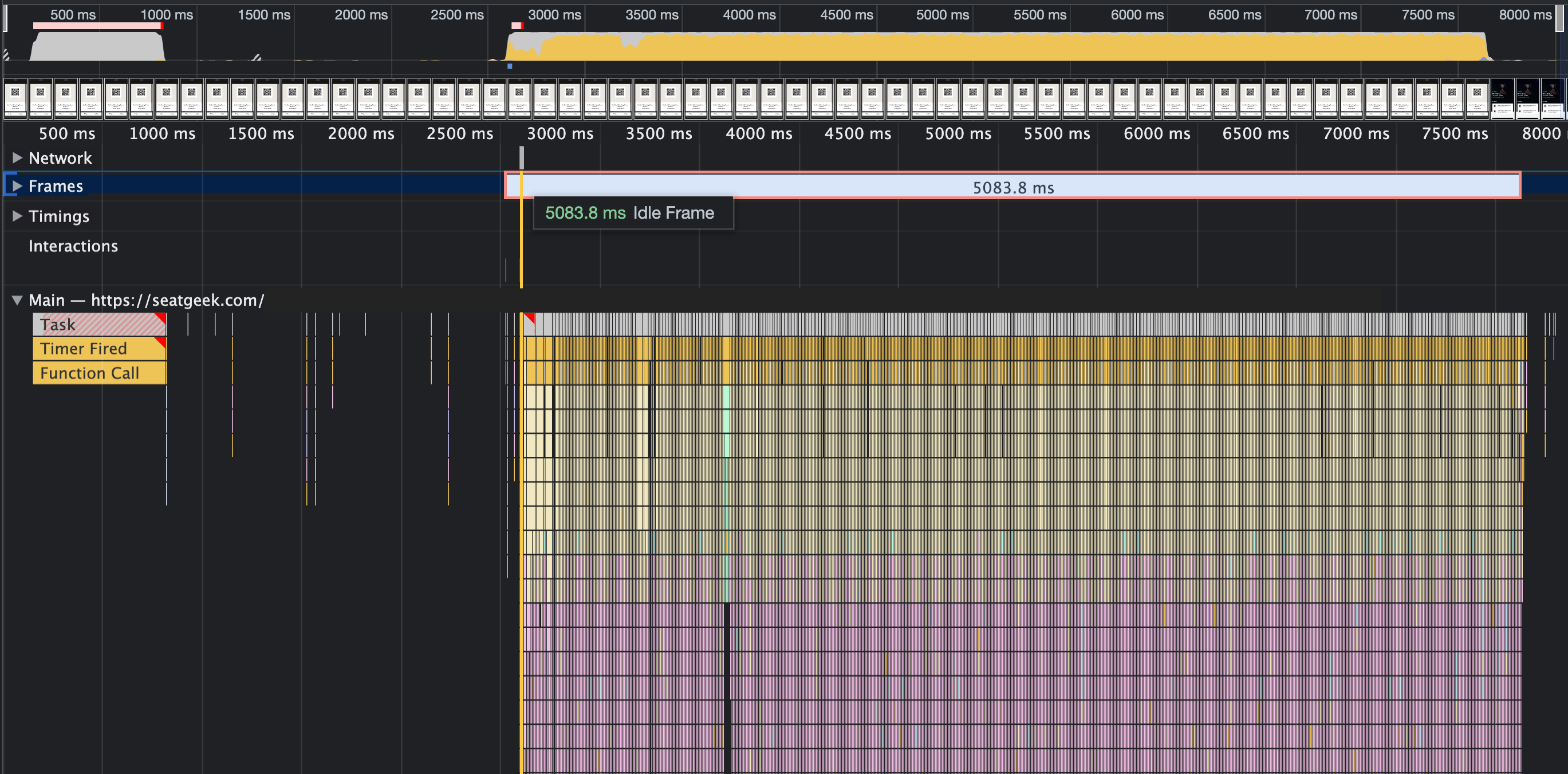
Post-release issue
While we devoted plenty of time to testing these changes in real environments, in the weeks that followed one issue was reported. Shallow routing via NextJS appeared to be 100x slower than normal.
5s Idle Frame while routing
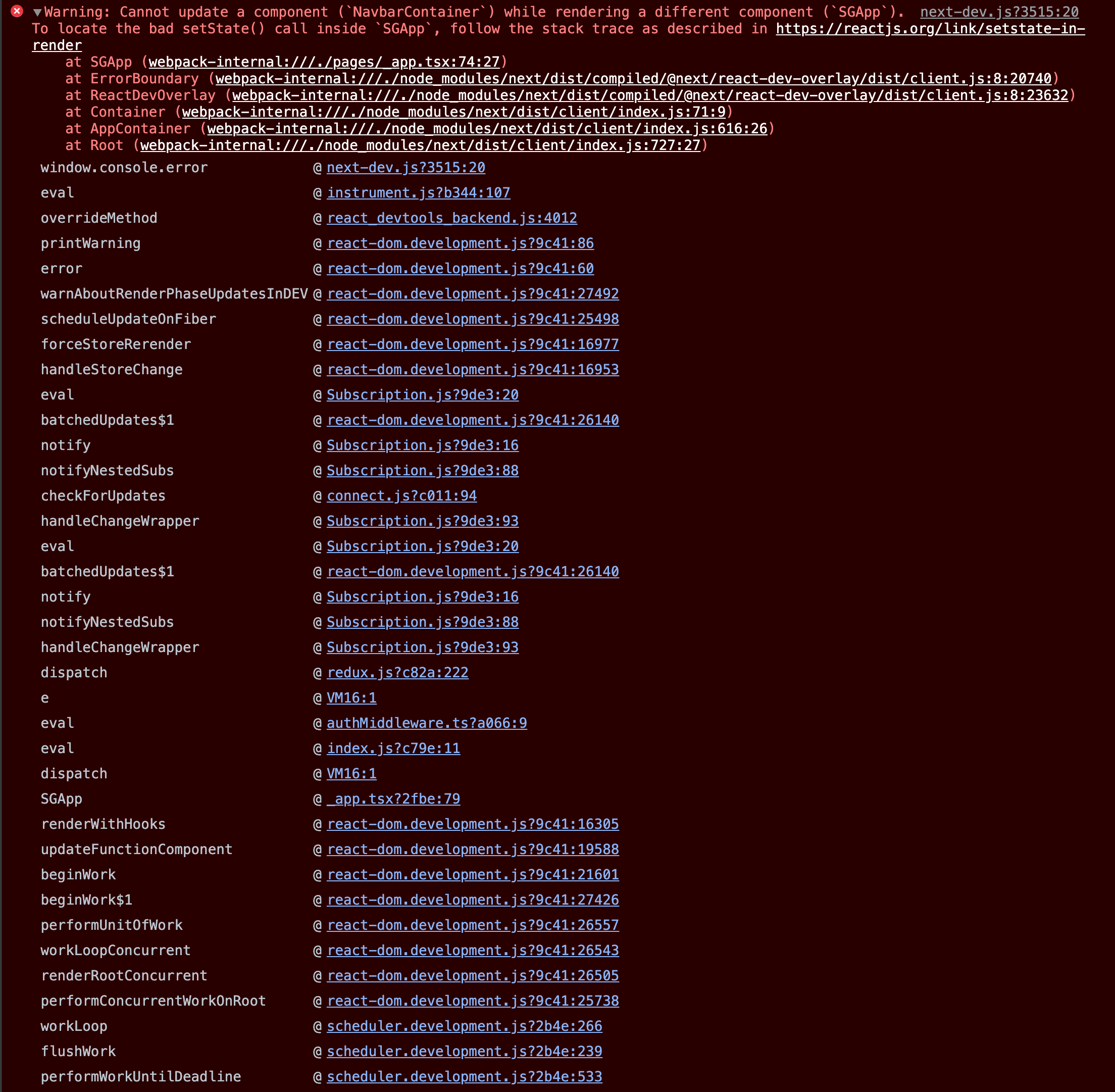
After further investigation, we came across the following stack trace.
React warning stack trace
React was telling us that something in the application was calling setState when it shouldn’t be. Reviewing the stack trace revealed that a redux dispatch was called while we were in the middle of routing. More so, it showed that this dispatch call was coming from the root _app file, used to initialize pages in NextJS. With this information we were able to identify two problematic dispatch calls in our root application that are fired every time we re-render our root. Reverting to React 17 proved to work as expected. So the question was, why was an upgrade to React 18 causing the entire app to re-render when we were performing a shallow route navigation via NextJS?
We still don’t know for certain what this specific issue was caused by, but we do believe this is related to using React 18 with NextJS. It appears that if you have a component that calls the useRouter hook, then even shallow routing will trigger those components to re-render, even if it happens to be the root of your application. We aren’t the only ones who have discovered this behavior either. We imagine in a future version of NextJS they will fix useRouter and avoid unnecessary re-rendering. For the time being, we were able to get rid of the inappropriate dispatch calls, and prevent the 100x slow down we experienced. Hopefully a future update will make shallow routing as reliable as it was prior to upgrading.
Conclusion
While we are now running React 18, we are far from finished. We have a lot of work to do to get our legacy code up to date, so future upgrades will be less burdensome. enzyme is low hanging fruit in that regard. React 18 included many new APIs, many of which our own libraries, have yet to take advantage of. Additionally, now that we are running on version 18, we can begin our upgrade to NextJS 13, unlocking even more potential for our developers and our customers alike.
We have covered most of what was required to upgrade seatgeek.com to React 18, you may face unique problems of your own when attempting it. Hopefully some of this has proved useful, and eases the upgrade path when you finally choose to upgrade.
Thanks for reading, and don’t hesitate to reach out. We are always looking for like-minded developers who are ready to push us onward and upward.
Last month, droves of Bruce Springsteen fans lined up at SeatGeek.com to buy tickets to see the Boss. It was one of our highest demand onsales in SeatGeek history, and it went by like a breeze, a success owed in part to our investment in browser-based load testing. We thought this would be a good opportunity to share how we built our own browser-based load testing tool to keep our software in tip-top shape using AWS Batch and Playwright at an astonishingly low price.
In a load test, we simulate the behavior of multiple users interacting with an application to see how that application responds to traffic. These users can be, and often are, simulated on the protocol level: a burst of purchases during a flash sale comes in the form of thousands of HTTP requests against a /purchase endpoint, a spike in sign-ons to a chatroom comes in the form of websocket connections, etc. This method for load testing is called protocol-based load testing and comes with a vast ecosystem of tooling, such as JMeter, Taurus, and Gatling. It is also relatively cheap to run: I, for example, can run a test that spawns a few thousand HTTP requests from my laptop without issues.
Browser-based load testing, alternatively, simulates users on the browser level: a burst of purchases during a flash sale comes in the form of thousands of real-life browser sessions connecting to our website and submitting purchases on its checkout page. Browser-based load testing allows us to simulate users more closely to how they actually behave and to decouple our tests from lower-level protocols and APIs, which may break or be entirely redesigned as we scale our systems.
But browser-based load testing comes with a much sparser tooling ecosystem. And, importantly, it is not so cheap: I, for example, can barely run one browser on my laptop without overheating; I wouldn’t ever dare to run one thousand. Once we get into the territory of requiring tens or hundreds of thousands of users for a test, even modern cloud solutions present difficulties in running the necessary compute to power so many browser sessions at once.
This post details how (and why) we built our own browser-based load testing tool using AWS Batch and Playwright to simulate 50,000+ users without breaking the bank.
Browser-based load testing at SeatGeek
The desire for browser-based load testing at SeatGeek began as we developed our in-house application for queueing users into high demand ticket onsales. You can learn more about the application in our QCon talk and podcast on the subject. In short, users who visit an event page for a high demand ticket onsale are served a special web application and granted a queue token that represents their place in line for the sale. The web application communicates with our backend via intermediary code that lives at the edge to exchange that queue token into an access token once the user is admitted entry, which allows the user to view the onsale’s event page. Edge cases, bottlenecks, and competing interests pile on complexity quickly and demand rapid iteration on how we fairly queue users into our site. Notice for a high demand onsale can come to us at any time, and we need to always be prepared to handle that traffic.
The one thing that remains fairly constant during all of this is the user’s experience on the browser. It’s crucially important that while we may change a request from polling to websockets, take use of some new feature from our CDN, or restructure how a lambda function consumes messages from a DynamoDB table, we never break our core feature: that tens of thousands of browsers can connect to a page and, after some time waiting in queue, all be allowed access to the protected resource.
We initially set up some protocol-based load tests but found it increasingly difficult to rely on those tests to catch the kind of performance issues and bugs that occur when real browsers set up websocket connections, emit heartbeats, reload pages, etc. We also found that the tests added overhead to our iteration cycles as we frequently experimented with new APIs and communication protocols to deal with increasing scale. What we wanted was a test like this:
I, a user, visit a page protected by our queueing software, say at /test-queue-page. I see some text like “The onsale will begin soon.”
An orchestrator process begins to allow traffic into the protected page
I wait some time and eventually see the protected page. Maybe I see the text “Buy tickets for test event.” If I don’t see the protected page within the allotted wait time, I consider the test to have failed.
Multiply me by X.
Why our own solution?
The test we want is simple enough, and it obviously will be a lot easier to pull off if we run it using one of the many established vendors in the performance testing world. So why did we decide to build the solution ourselves?
The key reason is cost. Not every load testing vendor offers browser-based tests, and those who do seem to optimize for tests that simulate tens to hundreds of users, not tens of thousands or more. In meetings with vendors, when we asked what it would cost to run one test with ~50,000 browsers for ~30 minutes (the max time we’d expect for a user to spend waiting for entry into an event), we were often quoted figures in the range of $15,000 to $100,000! And this was only a rough estimate: most vendors were not even sure if the test would be possible and provided an on-the-fly calculation of what the necessary resources would cost, which many times seemed like an attempt to dissuade us from the idea all together.
But we weren’t dissuaded so easily. Of course, we couldn’t justify spending tens of thousands of dollars on a performance test. At that price we could just pay 50,000 people a dollars each to log onto our site and text us what happens. Unfortunately, though, none of us had 50,000 friends. Instead, we turned to every developer’s best friend: AWS.
Picking a platform
At a given moment, we want to spawn ~50-100 thousand browsers, have them perform some given commands, and, at the least, report a success or failure condition. We also want a separate orchestrator process that can do some set up and tear down for the test, including spawning these browsers programmatically.
🚫 AWS Lambda
What is the hottest modern way to spawn short-lived compute jobs into the cloud? Lambda functions! Using Lambda was our first hunch, though we quickly ran into some blockers. To list a few:
Lambda functions have a strict 15 minute execution limit. We want to support browsers that live for longer than 15 minutes.
We found (and validated via the web) that the lambda runtime is not great at running chromium or other headless browsers.
Lambda doesn’t have a straightforward way of requesting a set number of invocations of one function concurrently.
✅ AWS Batch
AWS Batch, a newer AWS service intended for “[running] hundreds of thousands of batch computing jobs on AWS,” seemed to fit our requirements where Lambda failed to do so. According to their documentation:
AWS Batch dynamically provisions the optimal quantity and type of compute resources (e.g., CPU or memory optimized instances) based on the volume and specific resource requirements of the batch jobs submitted. With AWS Batch, there is no need to install and manage batch computing software or server clusters that you use to run your jobs, allowing you to focus on analyzing results and solving problems.
Unlike Lambda functions:
AWS Batch jobs have no maximum timeout.
EC2 instances, one of the available executors for Batch jobs, easily support running headless browsers.
AWS Batch’s array jobs allow a straightforward pattern for invoking a set number of workloads of a job definition.
Even better, Batch allows workloads to be run on spot instances - low-demand EC2 instance types provided at a discount price - allowing us to cut the cost of our compute up front.
If we ever urgently needed to run a high volume load test during low spot availability, we could always flip to on-demand EC2 instances for a higher price. To further save cost, we opted to run our Batch compute in a region with cheaper EC2 cost, given that at least in our initial iterations we had no dependencies on existing infrastructure. Also, if we were going to suddenly launch thousands of EC2 instances into our cloud, we thought it could be better to have a little isolation.
Here is a simplified configuration of our AWS Batch compute environment in terraform:
12345678910111213141516
resource "aws_batch_compute_environment" {
compute_environment_name_prefix = "load-test-compute-environment"
compute_resources {
// “optimal” will use instances from the C4, M4 and R4 instance families
instance_type = ["optimal"]
// select instances with a preference for the lowest-cost type
allocation_strategy = "BEST_FIT"
// it’s possible to only select spot instances if available at some discount threshold,
// though we prefer to use any compute that is available
bid_percentage = 100
max_vcpus = 10000
type = "EC2"
}
// we let AWS manage our underlying ECS instance for us
type = "MANAGED"
}
Implementation
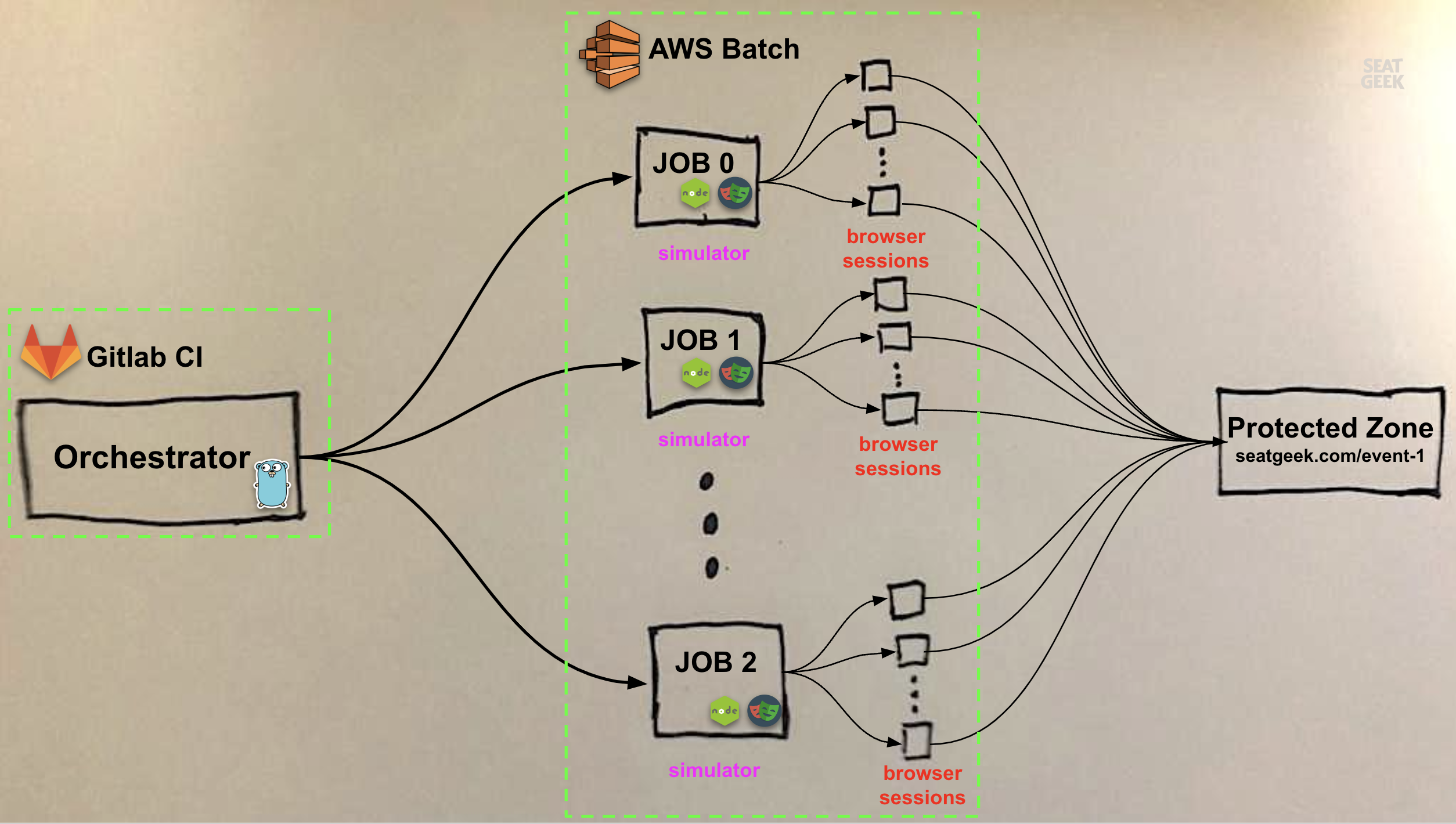
Our load test consists of two components: the simulator and the orchestrator.
The simulator is a small Node.js script that simulates a user’s behavior using Playwright and chromium. The simulated user visits a URL that is protected by our onsale queueing software and follows a set of steps before either returning successfully after arriving at the event page or emitting an error. This script is baked into a Docker image and deployed to AWS Batch as a job definition.
The orchestrator is a Go app that orchestrates the entire test execution. It both interacts with our onsale queuing software to control the protected resource under test and dispatches concurrent executions of the simulator to AWS Batch as an array job.
Outside of AWS Batch, we rely on our standard tooling to run the tests:
Gitlab CI runs the orchestrator as a scheduled CI/CD job, with some parameterization for toggling the number of simulated users (small-scale tests, for instance, run regularly as end-to-end tests; larger-scale tests require a manual invocation)
Datadog observes test executions and collects and aggregates data from browsers and orchestrator
Slack notifies stakeholders of test runs and results
Terraform provisions AWS Batch and related compute infrastructure
All together, our load test looks something like this:
Multiple browser sessions per Batch job
One caveat illustrated in the diagram above is that each simulator instance runs multiple browser sessions in parallel rather than a single browser. This is for three reasons. First, there is a floor on the CPU that can be allocated to an AWS Batch EC2 job: 1vCPU. We found that our browser only required about a tenth of 1vCPU to run. Let’s say Batch is attempting to schedule our jobs onto a fleet of m4.large instances, which can provision 2vCPU of compute and cost $0.10 an hour. To keep things simple, we’ll say we want to run 100,000 browsers for an hour. If each Batch job runs one browser, and each Batch job requires 1vCPU, we can only run two browsers per EC2 instance and will ultimately require 50,000 EC2 instances to run our test, costing us $5,000. If each job, instead, can run 10 browsers, we can run twenty browsers per EC2 instance and will only need 5,000 instances, reducing our cost to 10% of our original price.
Second, array jobs have a maximum of 10,000 child jobs, so if we want to run more than 10,000 users, we need to pack more than one browser session into each job. (Though even if Batch were to raise the limit of array child jobs to 100,000, we’d still need to run multiple browser sessions in parallel for cost reasons.)
Third, running multiple sessions on one browser means we can get more users using fewer resources: ten sessions running on one browser is cheaper than ten sessions each running on individual browsers.
One drawback of this approach is that we can’t rely on a one-to-one mapping of users→jobs to report per-user test behavior. To help us isolate failures, the simulator returns a non-zero exit code if any of its users fails, and each user emits logs with a unique user ID.
Another drawback is: what happens if nine of ten users in a simulator job succeed in passing through the queue in a minute, but the tenth queues for 30 minutes keeping the job alive? This is quite common, and we inevitably pay for the unused resources required to run the 9 finished users, since AWS Batch will hold that 1vCPU (as well as provisioned memory) for the entirety of the job’s run.
For now, running multiple browsers per job is a tradeoff we’re willing to make.
Abstractions on abstractions
One challenge in implementing our solution on Batch is that Batch involves many nested compute abstractions. To run jobs on Batch, a developer must first create a Compute Environment, which contains “the Amazon ECS container instances that are used to run containerized batch jobs”. We opted to use a Managed Compute Environment, in which AWS automatically provisions an ECS cluster based on a high-level specification of what resources we need to run our batch jobs. The ECS cluster then provisions an ASG to manage EC2 instances.
When running small workloads on Batch, this level of abstraction is likely not an issue, but given the more extreme demands of our load tests, we often hit bottlenecks that are not easy to track down. Errors on the ECS or ASG plane don’t clearly percolate up to Batch. An array job failing to move more than a given percentage of child jobs past the pending state can require sifting through logs from various AWS services. Ideally, Batch would more clearly surface some of these issues from underlying compute resources.
💸 Results
We have been able to reliably run ~30 minute tests with 60,000 browser-based users at less than $100. This is a massive improvement compared to the tens of thousands of dollars quoted by vendors. We run our high-traffic load test on a weekly cadence to catch major regressions and have more frequently scheduled, low-traffic tests throughout the week to keep a general pulse on our application.
Here is the total cost from our AWS region where we run our tests (we don’t run anything else in this region):
Conclusion
Browser-based load testing is a great way to realistically prepare web applications for high levels of traffic when protocol-based load testing won’t cut it. Moving forward we’d like to try extending our in-house testing tool to provide a more configurable testing foundation that can be used to test other critical paths in our web applications.
We hope our own exploration into this approach inspires teams to consider when browser-based load testing may be a good fit for their applications and how to do so without breaking the bank.
If you’re interested in helping us build browser-based load tests, check out our Jobs page at https://seatgeek.com/jobs. We’re hiring!
SeatGeek was started 12 years ago because we knew ticketing could be better. Since then, we’ve pushed the industry forward through product innovation: launching a top-rated mobile app, becoming the first to introduce fully dynamic maps, creating a metric to rate tickets by quality (now an industry norm) and introducing fully-interactive digital tickets with Rally. While our product is beloved by those who use it, the vast majority of fans have never heard of us.
So we think it’s time to bring the SeatGeek brand to the masses. To help us achieve this goal, we used this past year to rethink our brand strategy and reimagine our look and feel. We focused on creating something:
Bold like the events we ticket
Human like the emotions they evoke
Distinct from our competitive set
Confident in our expertise
See below for the full principles that guide our new brand:
Today, we’re excited to share SeatGeek’s new look. From our logo to our app and everything in between, our new brand represents everything SeatGeek is and what we bring to ticketing. Here are some of the foundational elements:
While technology has changed how we can experience live, our “why” for loving them is timeless; they are unpredictable, emotion driving, life in HD. Our tech expertise is lived out in the products we build, services we provide, and industry-shifting strategies we execute. To balance that, our new brand leans into that unchanging magic of live events. Retro concert posters, trading cards, tangible ticket mementos, lit-up marquees - we will take the opposite approach of the landscape right now, and “go back” to push forward.
We believe the new brand balances the innovation with the history, the modern with the retro, the future with the past. We accomplish this through a bold, yet approachable wordmark, a tangible color palette, an inviting tone of voice and more. All at the service of the die hards, the Deadheads, the rodeo fans, and the Broadway patrons alike. See below for examples of the new system in action:
We married our own obsession with the ticketing space with a diverse roster of talented partners that brought their own perspectives and inspirations, including Mother Design, Hoodzpah and Mickey Druzyj, to provide our internal team the tools to bring the rebrand to life across our many products and channels.
We believe great brands belong to the full organization, so to that end we ensured a broad group from across the organization was involved in the rebrand process. We’re excited to launch this rebrand as live events come back, and we believe they’re better than ever with SeatGeek.
Two years ago we wrote Refactoring Python with LibCST which documented SeatGeek’s first foray into building custom codemods to automate large-scale refactors of our codebases. We used the then-new LibCST library from Instagram to modernize thousands of lines of code in our consumer-facing Python applications.
This post details our newest venture: building custom codemods to automate large-scale refactors of our Go codebases. Go powers most of our Platform Engineering services, as well as some critical consumer-facing applications. We’ll discuss:
We recently shipped a new edge service at SeatGeek that allows us to better handle high-throughput events (like ticket onsales) without overloading our core infrastructure. The service is written in Go, is deployed to lambda + our CDN, and is dependent on several external services, like DynamoDB, Fastly and TimestreamDB.
We communicate with these services using their Go SDKs. When a call to a service fails, we “swap out” the error returned by the SDK with an internally-defined error that can be understood elsewhere in our application. Here is an example of what this might look like:
123456789
// an error defined in our applicationvarErrDynamoDBGetItem=fmt.Errorf("error getting item from dynamodb table")// somewhere in our appresult,err:=dynamoDBClient.GetItem(id)iferr!=nil{// return our own error that can be understood up the call stackreturnnil,ErrDynamoDBGetItem}
In a Python application, we could use Python’s exception chaining to propogate our own error (ErrDynamoDBGetItem) while preserving the data attached to the error returned by the DynamoDB SDK’s .GetItem(). But this is Go! Our errors are not so smart. If this code were running in production, we may suddenly see a burst of errors with the message "error getting item from dynamodb table" in our observability platform, but we wouldn’t know what caused that error, because any message attached to err has been lost. Is DynamoDB temporarily down? Is our DynamoDB table underprovisioned and timing out? Did we send an invalid query to DynamoDB? All of that context is lost when we replace err with ErrDynamoDBGetItem.
Go’s solution to this problem is “error wrapping.” We can return our own error, but Wrap it with the message returned from the DynamoDB SDK, like such:
12345678910111213
// import the "errors" packageimport"github.com/pkg/errors"// errors defined in our applicationvarErrDynamoDBGetItem=fmt.Errorf("error getting item from dynamodb table")// somewhere in our appresult,err:=dynamoDBClient.GetItem(id)iferr!=nil{// return our own error that can be understood up the call stack, preserving// the message in `err`.returnnil,errors.Wrap(ErrDynamoDBGetItem,err.Error())}
The change is fairly simple, and given this is a newer codebase, performing this refactor by hand wouldn’t be too difficult. The value of automating this refactor as a codemod is that we can ensure all code written in our application moving forward follows this new pattern and do so with minimal developer friction. If a developer pushes code that introduces an unwrapped error, we can catch it with our linter and flag it in CI. We can then use our codemod to update our code to make it production-ready.
If you’re looking for a full guide on writing a Go codemod, we recommend the article Using go/analysis to write a custom linter (which we followed in writing our codemod) and the official go/analysis docs. This section will delve into how we applied the go/analysis toolset to our refactor, but won’t give a complete tutorial on how to use the underlying tools.
The refactor
We’ve found it helpful when writing codemods to have a working mental model of our refactor before putting anything into code. Let’s start with the example we shared before:
123456789
// errors defined in our applicationvarErrDynamoDBGetItem=fmt.Errorf("error getting item from dynamodb table")// somewhere in our appresult,err:=dynamoDBClient.GetItem(id)iferr!=nil{// return our own error that can be understood up the call stackreturnnil,ErrDynamoDBGetItem}
If we try to put our desired refactor into words, we can say:
When we see an if block if err != nil {, we want to look through the statements in that if block’s body
When we find a return statement inside an if err != nil {, check if we’re returning an internal error type
All of our errors follow the Go convention of having the Err.* prefix, so this is a string comparison
Update that return value to errors.Wrap({ORIGINAL_RETURN_VALUE}, err.Error())
After parsing a file, if we’ve introduced any error wrapping, add the github.com/pkg/errors package to our imports
If the package is already imported, we can rely on our go formatter to squash the two imports together; there’s no need to stress over this functionality within our codemod
Now that we have a working mental model for our refactor, we can start to translate our refactor into the Go AST. An AST, or abstract syntax tree, is a tree representation of source code; most codemod tooling (that isn’t pure text search & replace) works by parsing source code, traversing and updating its AST, and then re-rendering the AST back to the file as source code.
Let’s look at our if err != nil {} expression to see how it would be represented in the Go AST. A quick text search in the Go AST docs for “if” finds the IfStmt struct. For now, we’re only concerned about the case where our if statement’s condition is (exactly) err != nil. (Once we’ve built out enough code to support this base case, we can iteratively add support for edge cases, for example, something like: err != nil && !config.SuppressErrors.) After some more time grokking the go/ast docs, it seems this is the node we’re looking for:
123456789101112
// An if statement with a binary expression that checks if a variable named "err" does not equal "nil"ast.IfStmt{// a binary expression, e.g. `5 + 2` or `event_type == "Concert"`Cond:&ast.BinaryExpr{// errX:&ast.Ident{Name:"err"},// !=Op:token.NEQ,// nilY:&ast.Ident{Name:"nil"},},}
Using go/analysis
go/ast provides the primitives needed for understanding Go source code as an AST, as we’ve just seen. go/analysis, on the other hand, provides the toolset used for traversing/modifying that tree, emitting messages to users, and generating CLIs for our codemod.
The primary type in the go/analysis API is the Analyzer. To define our error wrapping codemod, we create a new instance of the Analyzer struct, defining its name, user docs, dependencies and Run function - which will encapsulate our codemod logic.
12345678
varWrapErrorAnalyzer=&analysis.Analyzer{Name:"wrap_error",Doc:"check that new errors wrap context from existing errors in the call stack",Requires:[]*analysis.Analyzer{inspect.Analyzer},Run:func(pass*analysis.Pass)(interface{},error){...},}
Analyzer.Run houses our business logic and provides a low-level API for interacting with our parsed source code. The inspect.Analyzer dependency, which we require in WrapErrorAnalyzer.Requires, provides a more familiar interface for traversing our AST: a depth-first traversal of our AST nodes.
When we call inspector.Nodes within Run, we walk each node of our AST (that is: every function, variable assignment, switch statement, and so on in our program). Nodes are “visited” twice, once when “pushing” downward in our depth-first search (this is the “visit” action) and once when we are returning back up our tree (this is the “leave” action). At any point we can use the pass parameter from Analyzer.Run to emit messages to the user or introduce code modification to the AST. We can also update local analyzer state, which we use in this case to remember whether or not we’ve introduced the errors.Wrap function when visiting an ast.IfStmt and therefore need to add the “errors” import when we leave our ast.File.
Check out the source code of WrapErrorAnalyzer to see how all of this looks in action.
go/analysis: The Good, the Bad, and the Ugly
The Good
go/analysis provides great tools for using and testing your analyzer. The singlechecker and multichecker packages allow you to create a CLI for any analysis.Analyzer with only a few lines of boilerplate code. Check out our main.go file.
The analysistest package provides utilities for testing analyzers, following a similar pattern to the one we used in our LibCST codemod tests. To create a test, we write example.go, a source file to run our codemod on, and example.go.golden, what we expect our file to look like after running our codemod. analysistest will automatically run our codemod on example.go and check that the output matches example.go.golden. Check out our test files.
The bad
While analysistest provides a solid testing framework, there are some difficulties in writing the example test files. All files live in a testdata/ directory, which means that all files are part of the same go package. Any package errors will break the test suite. This means that each test example must have unique symbol names to avoid conflicts (e.g. two files in testdata/ can’t both have func main() {}). We also struggled to get imports of third-party libraries to work: we couldn’t write a test file that imports from “github.com/pkg/errors” as it broke package loading, even if “github.com/pkg/errors” is in our repo’s go.mod.
go/analysis lacks an API similar to LibCSTs matching API, which provides a declarative “way of asking whether a particular LibCST node and its children match a particular shape.” We’ve found that the matching API makes codemod code more accessible and reduces complexity of long, imperative functions to check if a node matches a given shape. For an example of how a matching API could improve our Go codemod, let’s look at our ifErrNeqNil function, which returns true if an IfStmt in our AST is an if err != nil{}.
This function works, but it’s a bit noisy (we need a go typecast for each side of the BinaryExpr). It also doesn’t lend itself well to evolution. What if we want to check for the binary expression nil != err? The size of our return statement doubles. What if we want to check for the case where our if statement condition chains multiple binary expressions, like: !config.SuppressErrors && err != nil? Our imperative function will become more complex and less clear in what it is checking.
If we imagine a golang matcher API, on the other hand, we can compose together declarative shapes of how we expect our AST to look, rather than write imperative logic to accomplish the same goal.
// imaginary packageimport"golang.org/x/tools/go/ast/imaginary/matcher"// matches: "err"varErrMatcher=matcher.Ident{"err"}// matches: "nil"varNilMatcher=matcher.Ident{"nil"}// matcher: err != nilvarErrNeqNilExactMatcher=matcher.BinaryExpr{X:ErrMatcher,Op:token.NEQ,Y:NilMatcher,}// matches: nil != errvarNilNeqErrExactMatcher=matcher.BinaryExpr{X:NilMatcher,Op:token.NEQ,Y:ErrMatcher,}// matches: either "err != nil" or "nil != err"varErrNeqNilMatcher=matcher.OneOf{Options:{ErrNeqNilExactMatcher,NilNeqErrExactMatcher,},}// matches: something like "!cfg.SuppressErrors && {ErrNeqNilMatcher}"varChainedBinaryMatcher=matcher.BinaryExpr{X:matcher.Any,Op:token.AND,Y:ErrNeqNilMatcher,}// matches our desired if statementvarDesiredIfStmtMatcher=matcher.IfStmt{Cond:matcher.OneOf{Options:{ErrNeqNilMatcher,ChainedBinaryMatcher,},},}// somewhere in our codemodifmatcher.Matches(ifStmt,DesiredIfStmtMatcher){// ...}
All we do here is declare some shapes we want to match in our parsed source code’s AST and let the matcher package perform the work of checking if a node in our AST matches that shape.
The ugly
To edit an AST using go/analysis, you emit a SuggestedFix. The SuggestedFix is, essentially, a list of pure text replacements within character ranges of your source code. This mix of traversing source code as an AST, but editing source code as text is… awkward. Updates to nodes deeper in the AST aren’t reflected when leaving nodes higher in the tree, as the underlying AST hasn’t actually been updated. Rather, the text edits are applied in one pass after the traversal of the tree is done. A consequence of this is noted in the docs for SuggestedFix: “TextEdits for a SuggestedFix should not overlap.” This could make writing codemods for more complex refactors, in which multiple nested nodes in the same AST may need to be updated, difficult (if not impossible). That being said, the SuggestedFix API is marked as Experimental; we’re curious to see how it develops moving forward.
If you’re interested in helping us build codemods for our codebase at scale, check out our Jobs page at https://seatgeek.com/jobs. We’re hiring!
Druzhba (PyPi, GitHub) is a friendly
framework for building data pipelines!
We couldn’t be more excited about our newest open source release. Today marks the coming of age of a tool that we’ve used
and appreciated for years.
If you speak Russian or Ukranian, you may have guessed at Druzhba’s purpose just from the name. Druzhba is the slavic
word for “friendship,” in addition to being the name of the word’s largest oil pipeline.
Our Druzhba efficiently carries data from production databases to data warehouses. At SeatGeek, it serves a crucial
role in our data systems, extracting data from hundreds of tables in our transactional databases and loading them into
our analytical data warehouse where they can be leveraged by the business.
We’ve prioritized simplicity and usability in building Druzhba, and the result is a tool that is easy to deploy and
maintain. A Druzhba pipeline is defined by a directory of YAML files that specify the connections
between the source and target databases. Over the years, we’ve added features that we found ourselves wishing for.
Some tools, for example, will require you to enumerate all the fields you want to copy, but Druzhba configurations
specify columns not to copy. Not only does this reduce upkeep and lines of code, it allows us to succinctly exclude
PII and other fields we’d rather leave out of our DWH.
Worried about copying from various source databases? Don’t be. Druzhba can unify your extract and load processes even
if your production databases use more than one RDBMS, and will help you persist data from production databases with
limited retention.
Running Druzhba is simple as well. Executing druzhba from your command line
will pull data from all your tables in all your sources databases. Running druzhba --database my_db --tables my_tables
would allow you to run just a subset of your pipelines. There are of course additional CLI options, and the instructions
for both configuring and running Druzhba can be found on our Read the Docs page.
You may have noticed that we used the words “extract” and “load” above, but there has as yet been no mention of “transform.”
Though Druzhba does support limited in-flight transformations, it isn’t primarily built according to an “Extract-Transform-Load” (ETL) pattern.
Instead, it’s designed to provide the first two steps in an “ELT” paradigm. Like many other organizations, we have come to strongly prefer ELT to ETL.
Recent years have seen tremendous improvements to database technology. Modern columnar Data Warehouse products are incredibly
powerful, and if a transform step can be expressed in SQL, data warehousing products are likely to achieve better performance
than any other tool.
In the absence of technical limitations, we’ve found that the right place for a transform step is almost always
as close to the end of the pipeline as possible. Transformation logic, especially business logic, tends to change.
Having as few pieces of the puzzle live dowstream of the transformation makes these changes easier and safer to implement.
So we perform our transformation steps - with the help of DBT - in our analytical data
warehouse after Druzhba’s work has been done.
Our data pipeline uses Druzhba for copying relational data from production to analytics while also leveraging
Luigi to load data from cloud services and manage our more complex
dependency graphs. This is a pairing that’s worked quite well for us. If you’re just starting out, or if the maturation
of your stack has left you wishing for a clean alternative to your homemade SQL ETL, Druzhba could work well for you too.
For more on how best to use Druzhba, check out the Readme.
Now that Druzhba is available for general use, we are looking forward to learning from your extensions and implementations.
If this is the sort of product you’d want to spend more time with, consider applying to our open
Data Engineer role, and stay tuned for more exciting SeatGeek engineering updates
here on ChairNerd!
In this article we’ll explore a pattern we used at SeatGeek to improve
performance and resilience for our feature-flags service implementation and to
reduce the amount of code needed on each application by externalizing the
retrying, caching, and persisting responsibilities to another process. We
decided to describe this pattern as we feel like it has several interesting use
cases for runtime application configuration.
Runtime Configuration Management
A typical pattern for distributed applications is to externalize configuration
into a centralized service other applications can pull data from. This pattern
was termed the External Configuration Store pattern
which can be summarized as follows
Move configuration information out of the application deployment package to
a centralized location. This can provide opportunities for easier management
and control of configuration data, and for sharing configuration data across
applications and application instances.
External Configuration in a Microservices world
One of the challenges of the external Configuration Store Pattern, when using for
distributed applications using microservices, is the selection of the delivery
mechanism. While the pattern page suggests using a backing store with acceptable
performance, high availability and that can be backed up; it does not make any
suggestions as to what that store might be and makes no reference at how
applications can pull the configuration data at runtime.
A typical setup is to use HTTP as the delivery mechanism for the configuration
data. Applications periodically poll the configuration store and optionally keep
a local read cache to speed up reads in between requests. This is, for example,
how the Envoy Proxy pulls configuration data from an external store to discover
hosts it needs to route requests to:
Each proxy instance connects to one of the highly available
configuration store servers and pulls the latest configuration data
periodically. Even though this is a redundant and highly available setup, each
envoy proxy instance still needs to deal with servers going away, timeouts,
retries and the occasional slow response due to network latency. The
configuration store also needs to be provisioned according to how many instances
of Envoy proxy servers are pulling data and how frequently the data needs to be
refreshed.
While all of those are known challenges and can be technically solved, the
operational cost of running an external configuration store can be significant,
especially if the data they serve is part of any critical code path.
When delivering configuration data over HTTP or similar transports such as gRPc
or S3 to multiple applications written in different languages, we find an additional
problem. Each application is responsible for implementing the retry,
timeouts and caching strategies, with the almost inevitable outcome that the
strategies eventually diverge.
The duplicated efforts and diverging implementations can also lead to increased
costs and hidden bugs. For instance, let’s evaluate an open-source software for
delivering feature toggles.
The Unleash HTTP server is a product implementing
the external configuration store pattern, it serves feature toggles over an HTTP
API that clients can consume locally.
Unleash offers many official client implementations, mostly contributed by the
community. Some of them periodically poll the API server,
and some others use a read-through cache.
Since it is easy to forget that networking errors are expected in distributed
applications, most of those clients implement no retry strategies, potentially
leaving applications with no configuration data.
While those problems can be attributed to programming errors that can be solved
by making the clients more robust, the point remains that the external
configuration store pattern presents the potential for diverging implementations
in the same system and duplicated efforts.
Distributing Configuration Data over SQL
A technology that is pervasive among both old and modern applications, that has had
decades of tuning and has robust clients for all languages used in the industry,
is a Relational Database. Such characteristics make relational databases great
candidates for storing, querying and delivering configuration data changes.
Querying relational databases is common knowledge for the majority of teams, and
so are the techniques for making databases highly available, and dealing with
errors. Many languages offer libraries implementing best practices for accessing
data in relational databases in a safe and resilient way.
We can make an addition to the External Configuration Store pattern to expressly
suggest delivering the configuration data via a relational database. The rest of
the pattern remains the same, just that we add an extra piece to the
architecture which copies the configuration data from the centralized store
into many distributed applications.
In this pattern, we introduce a worker service that copies a representation of
the current configuration data into each application database and keeps the data
up to date with changes from the centralized source.
Applications read directly from their local database using standard querying tools
for their languages, which significantly simplifies the access pattern for
configuration data. They also benefit from not having to implement
additional authentication mechanisms or store other credentials for pulling
configuration data from the centralized store. Moreover, they benefit from
any efforts to make the application database highly available.
Finally, one of the main advantages of this pattern is improved resiliency.
Since we have now mirrored the data on each application database, the source
storage can be down for any arbitrary amount of time without affecting the
availability of the latest known configuration data for each application.
This is especially true for applications being restarted or deployed while there
is an external configuration source outage. Given that a popular technique is to
request configuration data on application startup, we can guarantee that there
is workable configuration data on startup even in the face of a
configuration service outage.
We kept the centralized storage and distributed a worker service to each server
instances to subscribe for changes in the source data and write the changes in a
normalized SQLite database in the local file system. All containers in the same
host get the location for this SQLite database mounted as a volume that they can
read as a local file.
At SeatGeek, we have several services using feature-toggles to determine runtime
behavior of the code. Many of those services are written in languages other than
Python, our default language for new services. Thanks to SQLite having an
implementation for all of the languages we use in production, reading from the
feature-toggles database is just a matter of using a simple SQL query.
By storing the feature toggles in a local database, we dramatically improved the
resiliency of our applications by preventing missing configuration whenever the
external store was unavailable.
One particular scenario that we can now handle confidently is deploying
application instances while having the feature flags down for maintenance or
when it is experiencing an outage. In the past, we were caching feature flag
values in Redis for a short period of time, but once the cached value
expired, we had to use a fallback value whenever the feature-flags service was
down.
While Unleash tries to solve this issue by locally caching the feature flag
values as a JSON file, given our containerized architecture, the local cache
would not be transferred to a new application instance after a new deployment.
By externalizing the caching of the values using a push-model, we can remove the
specialized code dealing with these cases in each application.
It also simplified the implementation of the
feature flags clients, as the caching strategies and polling intervals became
irrelevant due to the great performance of SQLite databases.
You work in an organization with multiple teams needed to pull data from a
central configuration storage and you want to enforce externally availability
and performance guarantees without relying on teams implementing correctly
strategies for pulling the configuration data from the central storage.
You need near real-time configuration data changes or the rate of change of
the configuration data is frequent enough that applications need to poll the
storage more frequently than you can afford.
You have applications in distant regions of the globe and want to cheaply
Implement fast access to configuration data stored in another region.
You wish to enable applications to search, filter or select only partial fields
from your configuration data and your configuration provider does not allow such
operations.
You would like to have the configuration data available in your database so
you can use JOINs with other tables in the system.
Conclusion
We have shown a powerful pattern that can be used to simplify runtime
configuration of applications by externalizing it via a relational database. In
our particular case, we used SQLite databases to implement a push-model cache,
which drastically improved resilience, performance and simplicity of our
feature-flags by implementing an external process to keep the databases up to
date.
After implementing this pattern for our feature-flags service, we were motivated
to investigate how this can be generalized for use cases beyond pure
configuration data. We are now exploring ways of distributing read-only APIs
through databases as a way to improve data locality and open up the possibility
of doing fast joins with data coming from heterogeneous sources. A future write
up about our findings coming soon!