A big number of the internal services we have at SeatGeek are running on Python 2, but with the end of life for this version being around the corner, and motivated by certain performance challenges we’ve had to face this year, we decided to spend some time investigating whether or not migrating to Python 3 was worth the effort. In particular, we use the Tornado framework and we noticed that the IOLoop was mysteriously getting stuck under high load scenarios. Would the story be any different with the new version of the language?
The process of migrating to Python 3
Migrating to python 3 was initially faster than expected, but turned out to be a tricky process in
the end. With the help of libraries like six, future and 2to3 most of the changes to be done
in the codebase can be mechanically done.
Originally we had selected the service responsible for normalizing ticket data from different markets to a single format as the target for the migration investigation, we ended up migrating the service responsible for fetching listings from all external markets instead. This was due to the fact that the service in question would exercise async IO operations more often than the more CPU bound service that normalizes the data. Based on many different individual reports on the Internet, this is one of the areas where performance should improve when combining tornado and python 3.
The process of migrating this service can be outlined as such:
-
Create a Dockerfile with python 3 support so that we can run the application in Nomad. We ended up using
pyenvinstead ofvirtualenvfor installing python as we’ve been having a smootheresperience with it in general on our local dev environements as of late. -
Migrate private dependencies to be compatible with pip 10. The new version of pip has a more strict build process, and installation failed with all of our private dependencies. We fixed this by adding a
Manifest.infile to most repositories involved as transitive dependencies. The changes were mostly concerned with explicitly marking the files and folders that should be included in the package. -
Migrate private dependencies to be compatible with both python 3 and python 2. This process was very straightforward to do, except for the cases where the transitive dependencies of our private repos were not compatible at all with python 3. A notable example is the
MySQL-pythonlibrary, which has no support for the newer python versions. A suitable replacement could be found in all instances, so this was not a show stopper. -
Finally, apply the
2to3script to the listings service and work through the failing test cases.
Things to look out for
In all of the migrated repositories, there were common broken things that required a common solution. This is a list of the things we can expect when migrating other services to python 3:
-
Importing modules with absolute or relative path resolution is error prone. The safest way of making a python module work correctly under both versions is to import all modules using the fully qualified name such as
from mylib.my_module import fooinstead ofimport foo from my_module -
Exceptions need to be caught with the syntax
except Exception as exinstead ofexcept Exception, e. This can be fixed automatically by the2to3script. -
The
iteritems()method on dictionaries is gone, it can be safely replaced in all instances with theitems()function. This can also be fixed automatically by2to3 -
The print function needs parentheses. This is also fixed by the
2to3script -
Functions like
filterandzipdo not return a list anymore, but an iterator object. Better convert those to list comprehensions. The2to3script can help a great deal with this. -
Modules such as
urllib, andhtml,StringIOand a bunch of others were renamed. While the2to3script helps finding and fixing those, I found that it left too many loose ends. I found using thesixlibrary instead for manually replacing the imports a lot better and cleaner too. -
The
json.loads()function is more strict and throws different errors when failing to decode. Usages of this functions should be reviewed manually for places where we are expecting an exception, and the proper exception should be caught. -
Unknown
strvsbytesproblems everywhere. This is the one issue that cannot be solved mechanically. Given how py2 treated strings as both bytes and plain text, there are any cases in the code base where using one or the other results in an error.
Fighting str vs bytes
As stated before, this will be the number one source of bugs once a project is running under python 3. After fixing a great deal one instances where the 2 types were used in an incompatible manner, We have a few suggestions for any future migration.
Most of the bugs can be traced back to getting data from external datasources and expect them to be strings instead of bytes. Since this is actually a reasonable assumption we can do the following:
- Add a thing wrapper to the redis library to have a
get_str()method. Replace all occurrences ofredis.get()withredis.get_str()in the code. - Whenever using the
requestslibrary, use the.json()function in the response instead of manually getting the body and then decoding it asjson(). - Look out for any data received from s3 or similar amazon service, the return value of these libraries is always bytes. Manually review that we are not comparing the returned value with static strings.
Infra problems
The creation of a docker image for python 3 proved to be more difficult than expected, due to our pervasive assumption everywhere in our deployment pipeline and internal scripts that only python 2 with virtualenv is used. After fixing and sometimes working around these assumptions in the deployment code, a robust docker image could be produced. My suggestion for the near term future is to remove these assumptions from our scripts:
- In our deployment tool, stop injecting the
PYTHONPATHandPYTHONHOMEenvironment variables. Let the dockerfiles do this instead. - Each
Makefileshould either drop the virtualenv assumption or add support for pyenv. - Consider using a
Pipfile.lockfile in all our repositories for more reproducible builds. - I could not make
gunicornwork for the service, either we need to invest more time tracing the root of the problem or find a replacement for it.
A possible replacement for gunicorn could be implemented with either of the following strategies:
-
Install a signal handler in the python services to catch the
SIGINTsignal. Once the signal is caught, make the_statusendpoint always return an error code. This will make consulunregisterthe allocation, which will cause no new traffic to be routed to it. -
Install
nginxon each allocation and make it the reverse proxy for the tornado server. Set upnginxto graceful shutdown onSIGINTor any other suitable signal.
Additional action points
During the process of migrating to python 3 we left a couple loose ends in order to save time. The first one is critical to the correct functioning of the logging system.
-
Currently logging
jsonusing the loggers provided by our base libraries is not reliable, for some unknown reason some of the loggers are setup to output plain text. More careful study of why using custom formatters is not automatically applied to all created loggers is required. -
Migrate the applications to tornado 5, which was better integration with the py3 built-in event loop. Under no circumstance use tornado
4.5.3as it has a serious bug under python 3. -
Find a solution to deploying services which serialize data using
pickle. The migrated service, for example, storespickledbinary strings in redis. We need to make sure both versions use different key paths, for the time both version are running concurrently.
Performance
In order to analyse the performance characteristics of python 2 vs python 3, we created a test where a single event’s listings are fetched through an aggregator service. The caching proxy was taken out of the mix so that I could see the service behaviour under heavy stress.
Using 40 service allocations (each one maps to roughly a single machine CPU), this is the result of using py2 vs py3:
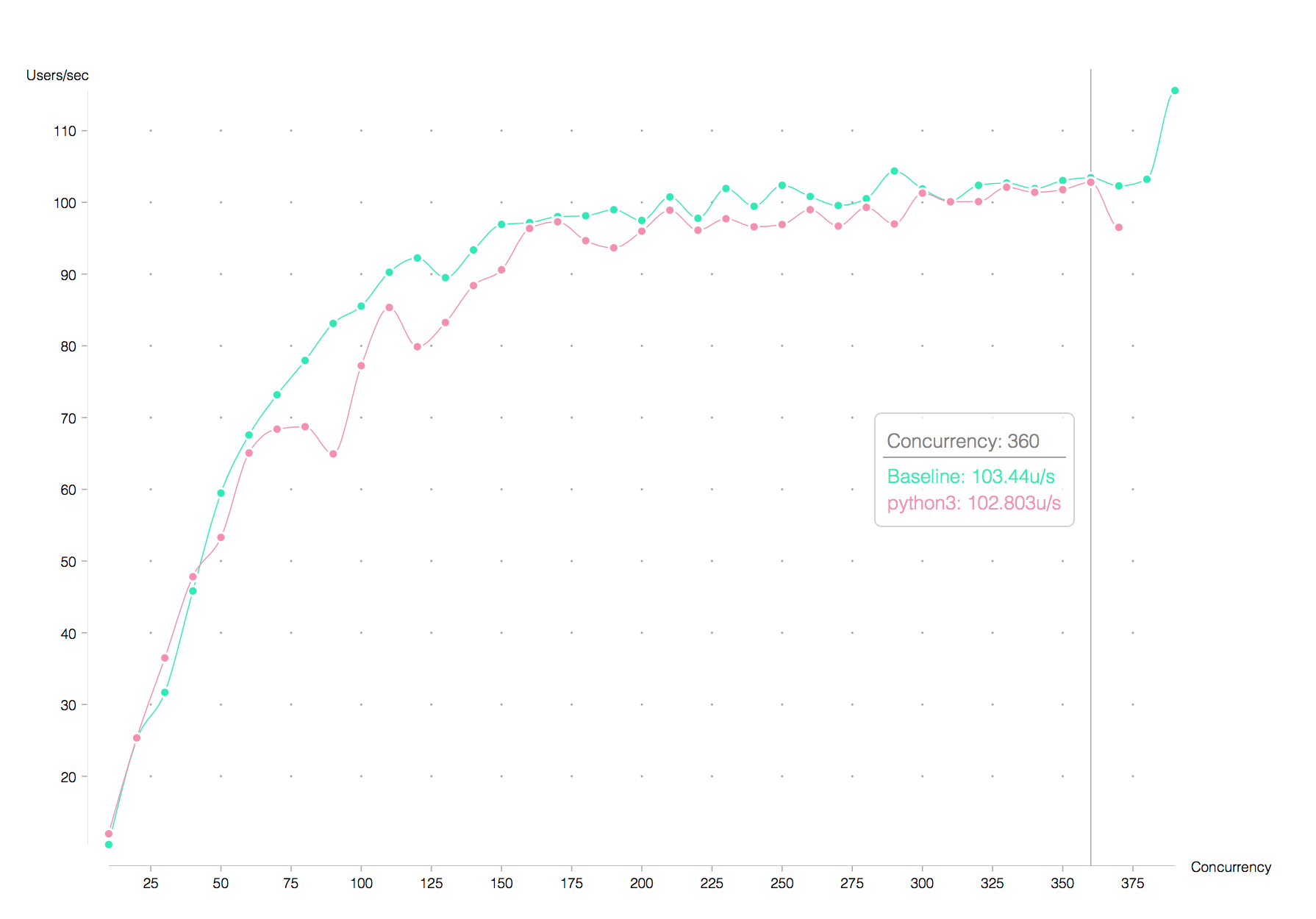
There seems to be an interesting performance difference at the beginning of the chart. It was also interesting that repeating the experiment yielded a similar graph:
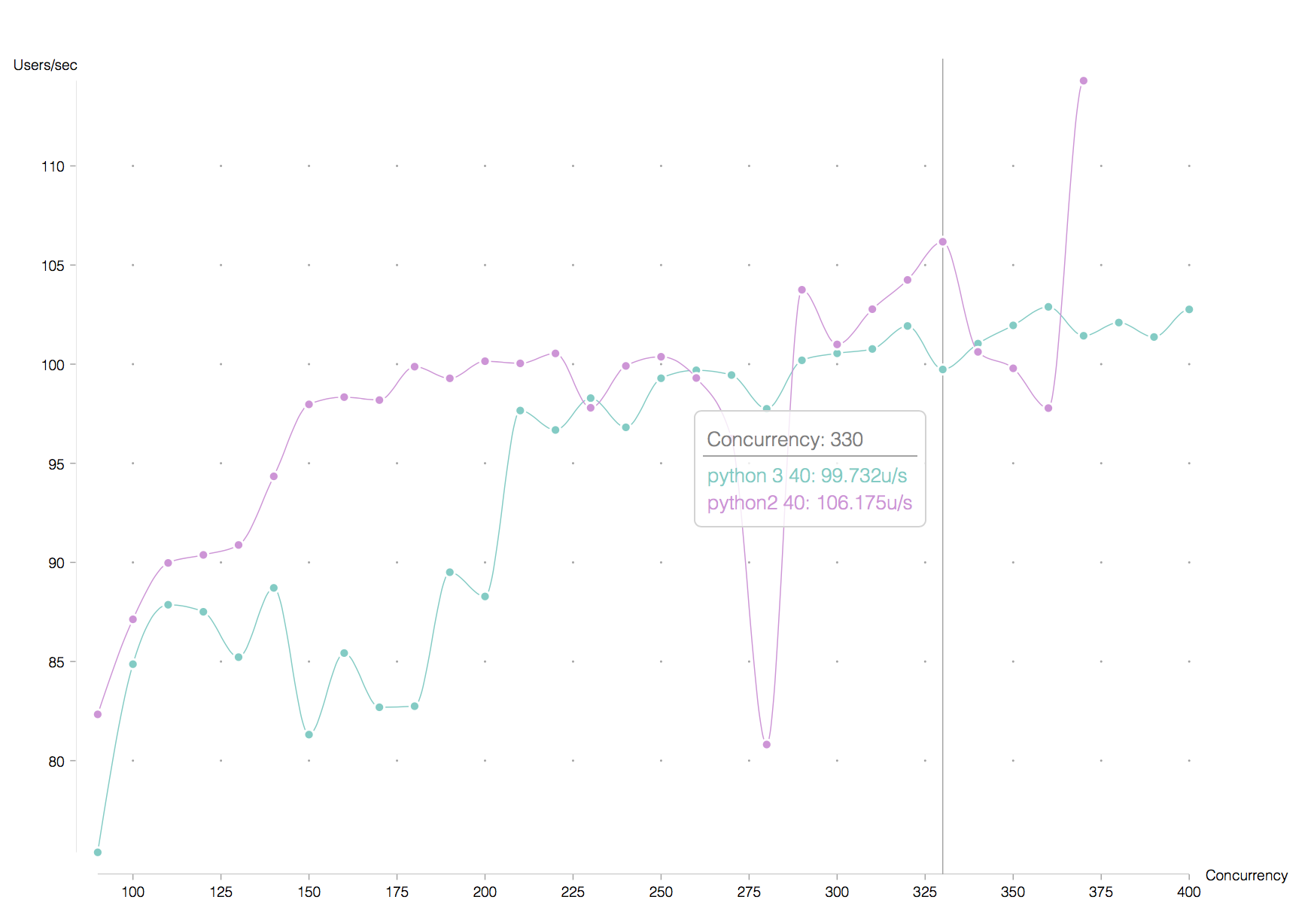
There is a chance that the difference between both lines is not actually due to the python versions,
but due to the absence of gunicorn in the python 3 service. This hypothesis is supported by the
next round of tests as will be shown below.
For both versions the bottleneck were their upstream services (tickenetwork, seller direct, etc.) so this test could not actually show the behaviour of both services under stress. We decided then that reducing the amount of allocations in half could then determine better whether python 3 can outperform python 2 in terms of efficiency. Here are the results:
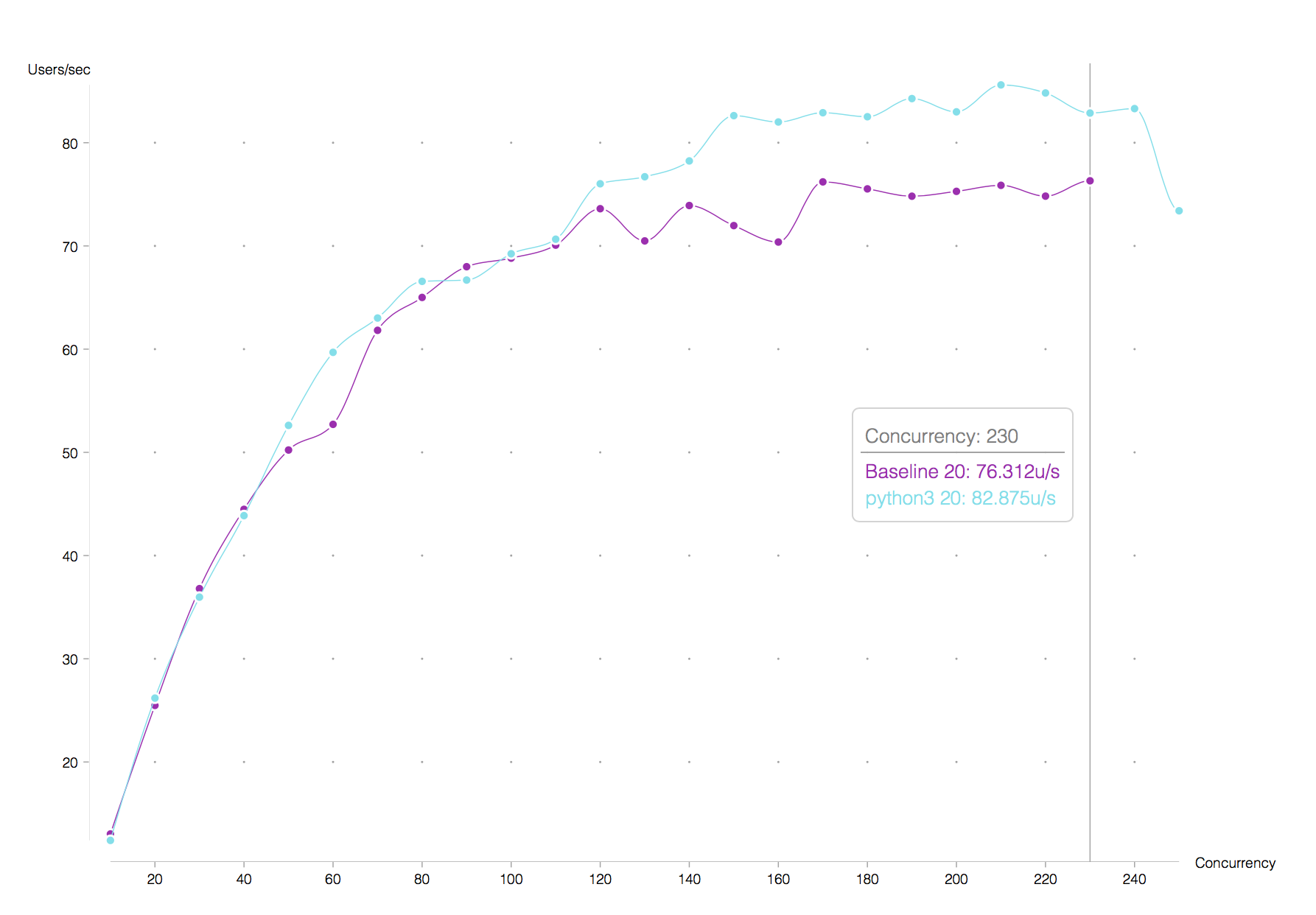
Similarly to he previous round of tests, the results are reproducible. Here’s another set of runs:
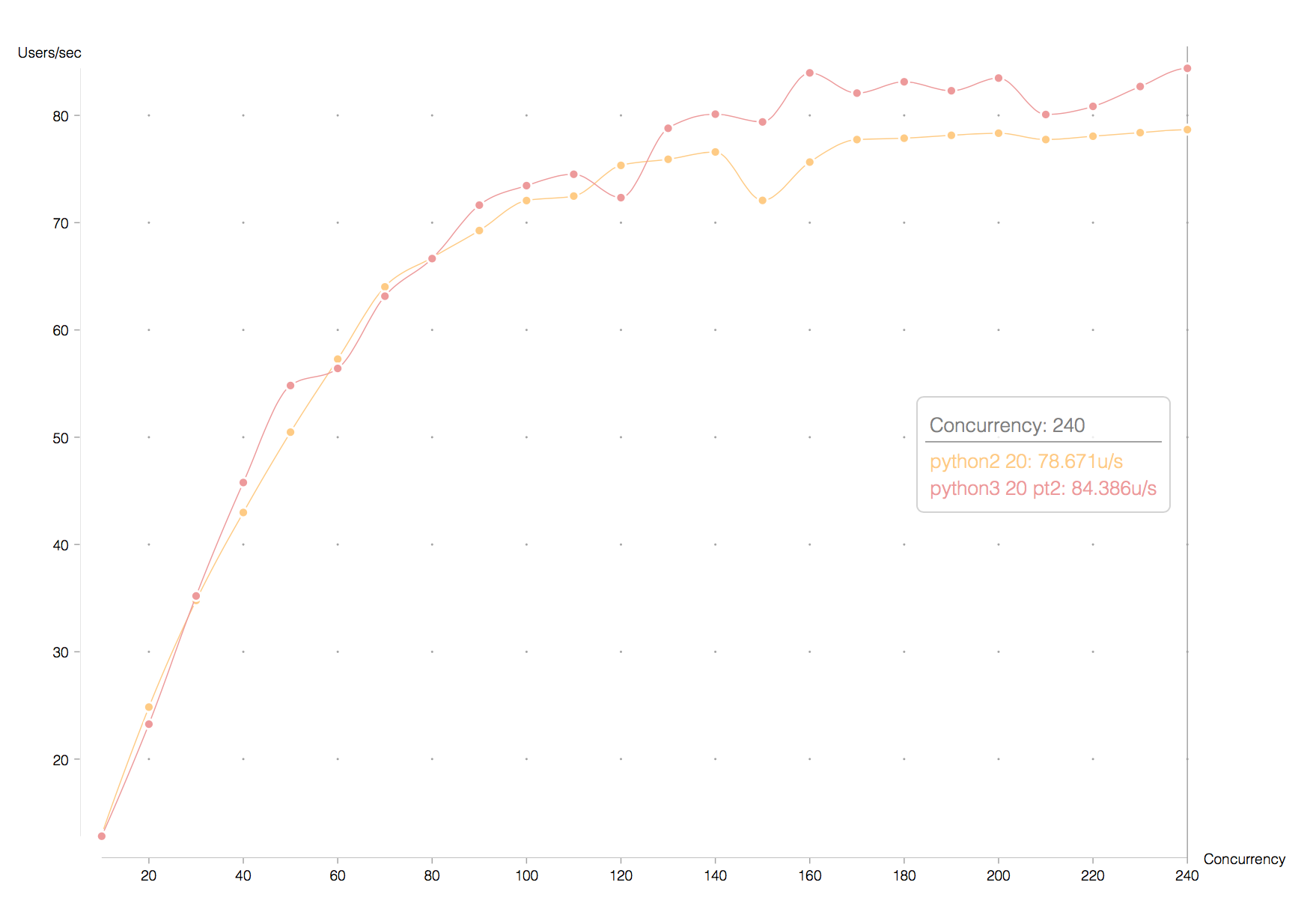
It is clear for the previous graphs that performance is identical under low concurrency situations.
Keep in mind that the low concurrency situation in this case corresponds to the double of the same
number in the previous tests, due to having half of the allocations to handle the same load. It is
encouraging to see that the difference is marginal, as we can claim more confidently that the difference
seen in the previous tests can be attributed to the way requests were being handled by gunicorn.
More interestingly in this case, we can see that under high concurrency, the python 3 service outperforms python 2 by around 5%. Who aggregating the number on minutes instead of seconds, the difference is more obvious:
Requests per minute during the python 3 test:
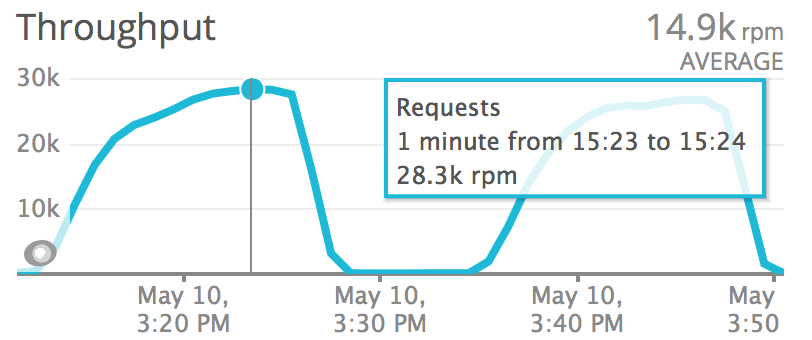
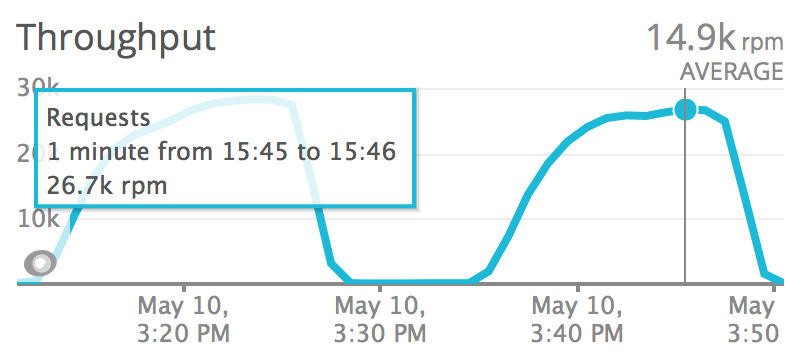
Requests per minute during the python 2 test:
We can also see that the time spent in python is less when using python 3:
![]()
The left part of the graph was the test running python 3 and the right part of the graph is the master branch of listingfeed.
We could conclude from this graph that python 3 is more efficient in the utilization of resources, leading to a small performance
advantage when under load. In none of the tests we could notice any significant CPU usage difference between the 2 versions,
which is to be expected for this IO bound service.
The bottom line
Migrating to python 3 only for performance benefits does not seem justifiable, at least not for applications like the listings service, but we can definitely expect to see a modest difference in performance when upgrading major versions.
On the other hand, benefits of using python 3 from the developer perspective may be more important than raw performance. There was a clear excitement by many members of the team when they saw we were working on migrating libraries to the new version.
Things like better typing support and static analysis tools may bring more robustness to our services and help us reduce the amount of regressions we commit to production.