Last month, droves of Bruce Springsteen fans lined up at SeatGeek.com to buy tickets to see the Boss. It was one of our highest demand onsales in SeatGeek history, and it went by like a breeze, a success owed in part to our investment in browser-based load testing. We thought this would be a good opportunity to share how we built our own browser-based load testing tool to keep our software in tip-top shape using AWS Batch and Playwright at an astonishingly low price.
In a load test, we simulate the behavior of multiple users interacting with an application to see how that application responds to traffic. These users can be, and often are, simulated on the protocol level: a burst of purchases during a flash sale comes in the form of thousands of HTTP requests against a /purchase endpoint, a spike in sign-ons to a chatroom comes in the form of websocket connections, etc. This method for load testing is called protocol-based load testing and comes with a vast ecosystem of tooling, such as JMeter, Taurus, and Gatling. It is also relatively cheap to run: I, for example, can run a test that spawns a few thousand HTTP requests from my laptop without issues.
Browser-based load testing, alternatively, simulates users on the browser level: a burst of purchases during a flash sale comes in the form of thousands of real-life browser sessions connecting to our website and submitting purchases on its checkout page. Browser-based load testing allows us to simulate users more closely to how they actually behave and to decouple our tests from lower-level protocols and APIs, which may break or be entirely redesigned as we scale our systems.
But browser-based load testing comes with a much sparser tooling ecosystem. And, importantly, it is not so cheap: I, for example, can barely run one browser on my laptop without overheating; I wouldn’t ever dare to run one thousand. Once we get into the territory of requiring tens or hundreds of thousands of users for a test, even modern cloud solutions present difficulties in running the necessary compute to power so many browser sessions at once.
This post details how (and why) we built our own browser-based load testing tool using AWS Batch and Playwright to simulate 50,000+ users without breaking the bank.
Browser-based load testing at SeatGeek
The desire for browser-based load testing at SeatGeek began as we developed our in-house application for queueing users into high demand ticket onsales. You can learn more about the application in our QCon talk and podcast on the subject. In short, users who visit an event page for a high demand ticket onsale are served a special web application and granted a queue token that represents their place in line for the sale. The web application communicates with our backend via intermediary code that lives at the edge to exchange that queue token into an access token once the user is admitted entry, which allows the user to view the onsale’s event page. Edge cases, bottlenecks, and competing interests pile on complexity quickly and demand rapid iteration on how we fairly queue users into our site. Notice for a high demand onsale can come to us at any time, and we need to always be prepared to handle that traffic.
The one thing that remains fairly constant during all of this is the user’s experience on the browser. It’s crucially important that while we may change a request from polling to websockets, take use of some new feature from our CDN, or restructure how a lambda function consumes messages from a DynamoDB table, we never break our core feature: that tens of thousands of browsers can connect to a page and, after some time waiting in queue, all be allowed access to the protected resource.
We initially set up some protocol-based load tests but found it increasingly difficult to rely on those tests to catch the kind of performance issues and bugs that occur when real browsers set up websocket connections, emit heartbeats, reload pages, etc. We also found that the tests added overhead to our iteration cycles as we frequently experimented with new APIs and communication protocols to deal with increasing scale. What we wanted was a test like this:
- I, a user, visit a page protected by our queueing software, say at
/test-queue-page. I see some text like “The onsale will begin soon.” - An orchestrator process begins to allow traffic into the protected page
- I wait some time and eventually see the protected page. Maybe I see the text “Buy tickets for test event.” If I don’t see the protected page within the allotted wait time, I consider the test to have failed.
- Multiply me by X.
Why our own solution?
The test we want is simple enough, and it obviously will be a lot easier to pull off if we run it using one of the many established vendors in the performance testing world. So why did we decide to build the solution ourselves?
The key reason is cost. Not every load testing vendor offers browser-based tests, and those who do seem to optimize for tests that simulate tens to hundreds of users, not tens of thousands or more. In meetings with vendors, when we asked what it would cost to run one test with ~50,000 browsers for ~30 minutes (the max time we’d expect for a user to spend waiting for entry into an event), we were often quoted figures in the range of $15,000 to $100,000! And this was only a rough estimate: most vendors were not even sure if the test would be possible and provided an on-the-fly calculation of what the necessary resources would cost, which many times seemed like an attempt to dissuade us from the idea all together.
But we weren’t dissuaded so easily. Of course, we couldn’t justify spending tens of thousands of dollars on a performance test. At that price we could just pay 50,000 people a dollars each to log onto our site and text us what happens. Unfortunately, though, none of us had 50,000 friends. Instead, we turned to every developer’s best friend: AWS.
Picking a platform
At a given moment, we want to spawn ~50-100 thousand browsers, have them perform some given commands, and, at the least, report a success or failure condition. We also want a separate orchestrator process that can do some set up and tear down for the test, including spawning these browsers programmatically.
🚫 AWS Lambda
What is the hottest modern way to spawn short-lived compute jobs into the cloud? Lambda functions! Using Lambda was our first hunch, though we quickly ran into some blockers. To list a few:
- Lambda functions have a strict 15 minute execution limit. We want to support browsers that live for longer than 15 minutes.
- We found (and validated via the web) that the lambda runtime is not great at running chromium or other headless browsers.
- Lambda doesn’t have a straightforward way of requesting a set number of invocations of one function concurrently.
✅ AWS Batch
AWS Batch, a newer AWS service intended for “[running] hundreds of thousands of batch computing jobs on AWS,” seemed to fit our requirements where Lambda failed to do so. According to their documentation:
AWS Batch dynamically provisions the optimal quantity and type of compute resources (e.g., CPU or memory optimized instances) based on the volume and specific resource requirements of the batch jobs submitted. With AWS Batch, there is no need to install and manage batch computing software or server clusters that you use to run your jobs, allowing you to focus on analyzing results and solving problems.
Unlike Lambda functions:
- AWS Batch jobs have no maximum timeout.
- EC2 instances, one of the available executors for Batch jobs, easily support running headless browsers.
- AWS Batch’s array jobs allow a straightforward pattern for invoking a set number of workloads of a job definition.
Even better, Batch allows workloads to be run on spot instances - low-demand EC2 instance types provided at a discount price - allowing us to cut the cost of our compute up front.
If we ever urgently needed to run a high volume load test during low spot availability, we could always flip to on-demand EC2 instances for a higher price. To further save cost, we opted to run our Batch compute in a region with cheaper EC2 cost, given that at least in our initial iterations we had no dependencies on existing infrastructure. Also, if we were going to suddenly launch thousands of EC2 instances into our cloud, we thought it could be better to have a little isolation.
Here is a simplified configuration of our AWS Batch compute environment in terraform:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
Implementation
Our load test consists of two components: the simulator and the orchestrator.
The simulator is a small Node.js script that simulates a user’s behavior using Playwright and chromium. The simulated user visits a URL that is protected by our onsale queueing software and follows a set of steps before either returning successfully after arriving at the event page or emitting an error. This script is baked into a Docker image and deployed to AWS Batch as a job definition.
The orchestrator is a Go app that orchestrates the entire test execution. It both interacts with our onsale queuing software to control the protected resource under test and dispatches concurrent executions of the simulator to AWS Batch as an array job.
Outside of AWS Batch, we rely on our standard tooling to run the tests:
- Gitlab CI runs the orchestrator as a scheduled CI/CD job, with some parameterization for toggling the number of simulated users (small-scale tests, for instance, run regularly as end-to-end tests; larger-scale tests require a manual invocation)
- Datadog observes test executions and collects and aggregates data from browsers and orchestrator
- Slack notifies stakeholders of test runs and results
- Terraform provisions AWS Batch and related compute infrastructure
All together, our load test looks something like this:
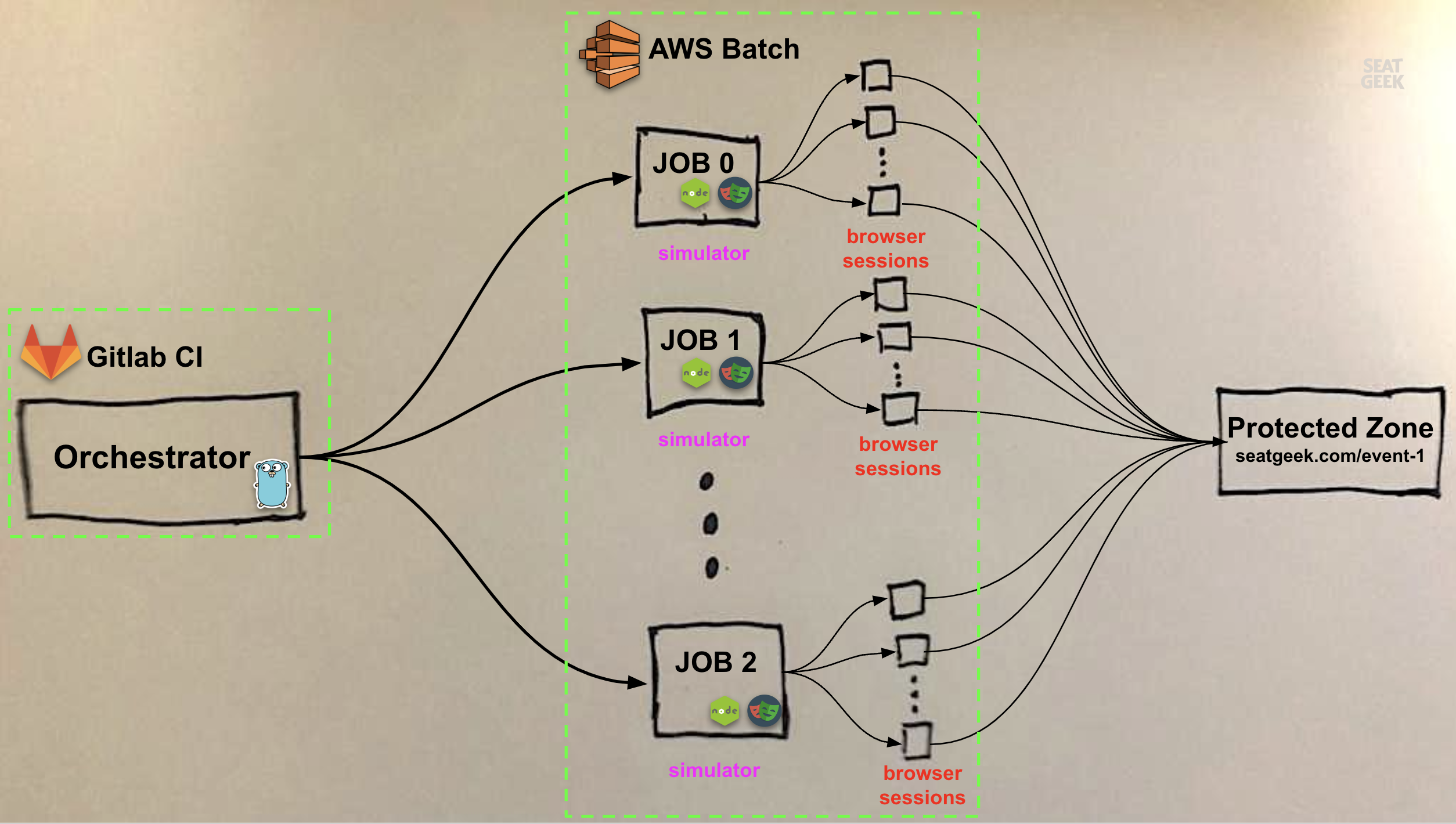
Multiple browser sessions per Batch job
One caveat illustrated in the diagram above is that each simulator instance runs multiple browser sessions in parallel rather than a single browser. This is for three reasons. First, there is a floor on the CPU that can be allocated to an AWS Batch EC2 job: 1vCPU. We found that our browser only required about a tenth of 1vCPU to run. Let’s say Batch is attempting to schedule our jobs onto a fleet of m4.large instances, which can provision 2vCPU of compute and cost $0.10 an hour. To keep things simple, we’ll say we want to run 100,000 browsers for an hour. If each Batch job runs one browser, and each Batch job requires 1vCPU, we can only run two browsers per EC2 instance and will ultimately require 50,000 EC2 instances to run our test, costing us $5,000. If each job, instead, can run 10 browsers, we can run twenty browsers per EC2 instance and will only need 5,000 instances, reducing our cost to 10% of our original price.
Second, array jobs have a maximum of 10,000 child jobs, so if we want to run more than 10,000 users, we need to pack more than one browser session into each job. (Though even if Batch were to raise the limit of array child jobs to 100,000, we’d still need to run multiple browser sessions in parallel for cost reasons.)
Third, running multiple sessions on one browser means we can get more users using fewer resources: ten sessions running on one browser is cheaper than ten sessions each running on individual browsers.
One drawback of this approach is that we can’t rely on a one-to-one mapping of users→jobs to report per-user test behavior. To help us isolate failures, the simulator returns a non-zero exit code if any of its users fails, and each user emits logs with a unique user ID.
Another drawback is: what happens if nine of ten users in a simulator job succeed in passing through the queue in a minute, but the tenth queues for 30 minutes keeping the job alive? This is quite common, and we inevitably pay for the unused resources required to run the 9 finished users, since AWS Batch will hold that 1vCPU (as well as provisioned memory) for the entirety of the job’s run.
For now, running multiple browsers per job is a tradeoff we’re willing to make.
Abstractions on abstractions
One challenge in implementing our solution on Batch is that Batch involves many nested compute abstractions. To run jobs on Batch, a developer must first create a Compute Environment, which contains “the Amazon ECS container instances that are used to run containerized batch jobs”. We opted to use a Managed Compute Environment, in which AWS automatically provisions an ECS cluster based on a high-level specification of what resources we need to run our batch jobs. The ECS cluster then provisions an ASG to manage EC2 instances.
When running small workloads on Batch, this level of abstraction is likely not an issue, but given the more extreme demands of our load tests, we often hit bottlenecks that are not easy to track down. Errors on the ECS or ASG plane don’t clearly percolate up to Batch. An array job failing to move more than a given percentage of child jobs past the pending state can require sifting through logs from various AWS services. Ideally, Batch would more clearly surface some of these issues from underlying compute resources.
💸 Results
We have been able to reliably run ~30 minute tests with 60,000 browser-based users at less than $100. This is a massive improvement compared to the tens of thousands of dollars quoted by vendors. We run our high-traffic load test on a weekly cadence to catch major regressions and have more frequently scheduled, low-traffic tests throughout the week to keep a general pulse on our application.
Here is the total cost from our AWS region where we run our tests (we don’t run anything else in this region):

Conclusion
Browser-based load testing is a great way to realistically prepare web applications for high levels of traffic when protocol-based load testing won’t cut it. Moving forward we’d like to try extending our in-house testing tool to provide a more configurable testing foundation that can be used to test other critical paths in our web applications.
We hope our own exploration into this approach inspires teams to consider when browser-based load testing may be a good fit for their applications and how to do so without breaking the bank.
If you’re interested in helping us build browser-based load tests, check out our Jobs page at https://seatgeek.com/jobs. We’re hiring!