Introduction: Chasing Better CI at Scale
Continuous Integration (CI) pipelines are one of the foundations of a good developer experience. At SeatGeek, we’ve leaned heavily on CI to keep developers productive and shipping code safely.
Earlier this year, we made a big push to modernize our stack by moving from using Nomad for orchestration to using Kubernetes to orchestrate all of our workloads across SeatGeek. When we started migrating our workloads to Kubernetes, we saw the perfect opportunity to reimagine how our CI runners worked. This post dives into our journey of modernizing CI at SeatGeek: the problems we faced, the architecture we landed on, and how we navigated the migration for 600+ repositories without slowing down development.
A Bit of History: From Nomad to Kubernetes
For years, we used Nomad to orchestrate runners at SeatGeek. We used fixed scaling to run ~80 hosts on weekdays and ~10 hosts on weekends. Each host would run one job at a time, so hosts were either running a job or waiting on a job.
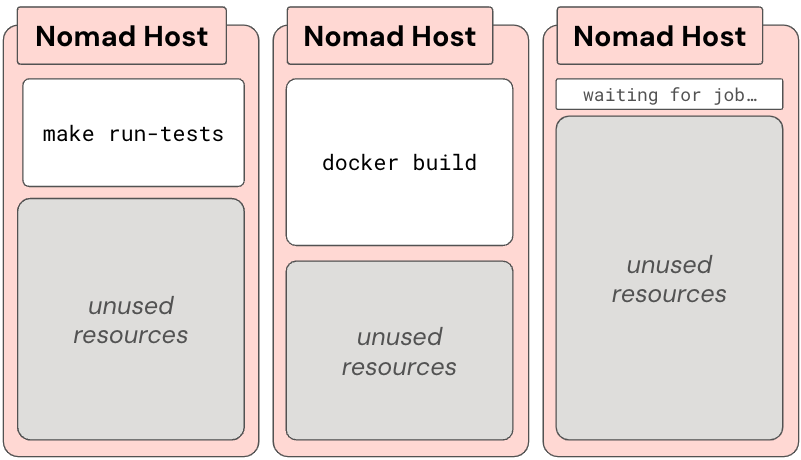
This architecture got the job done but not without its quirks. Over time, we started to really feel some pain points in our CI setup:
- Wasted Resources (and Money): Idle runners sat around, waiting for work, not adjusting to demand in real-time.
- Long Queue Times: During peak working hours, developers waited… and sometimes waited a bit more. Productivity suffered.
- State Pollution: Jobs stepped on each other’s toes, corrupting shared resources, and generally causing instability.
We decided to address these pain points head-on. What we wanted was simple: a CI architecture that was fast, efficient, and resilient. We needed a platform that could keep up with our engineering needs as we scaled.
New Architecture: Kubernetes-Powered Runners
After evaluating a few options, we landed on using the GitLab Kubernetes Executor to dynamically spin up ephemeral pods for each CI job. Here’s how it works at a high level:
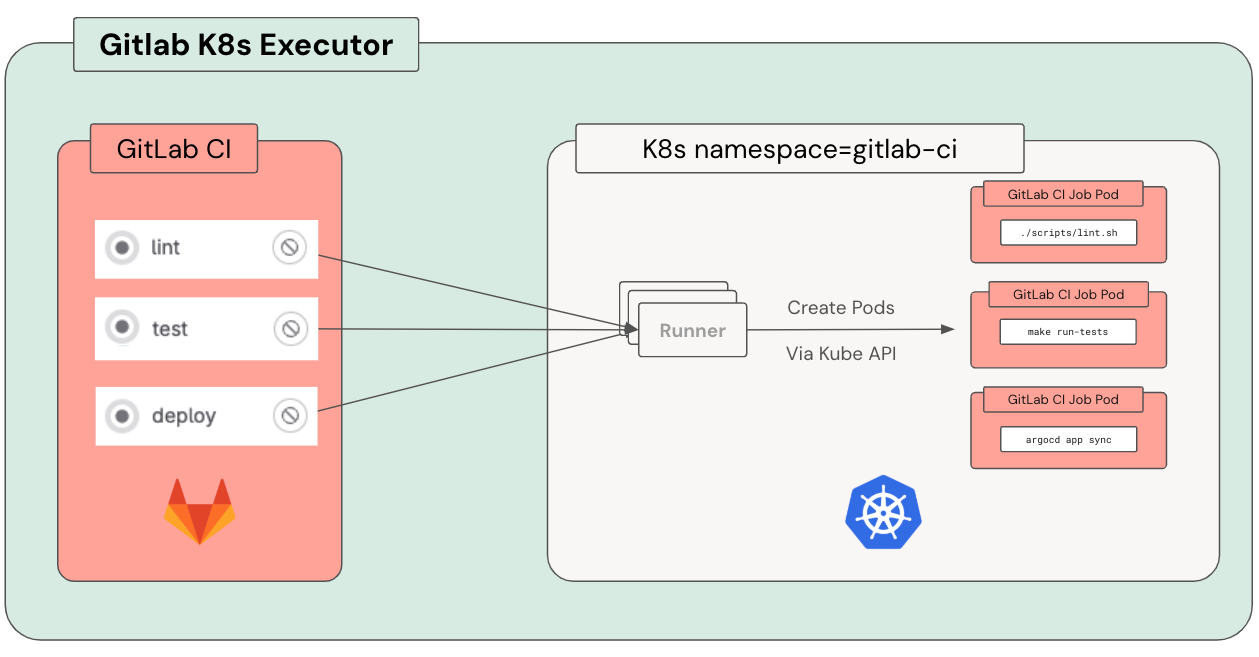
Each CI job gets its own pod, with containers for:
- Build: Runs the job script.
- Helper: Handles git operations, caching, and artifacts.
- Svc-x: Any service containers defined in the CI config (eg databases, queues, etc).
Using ephemeral pods eliminated resource waste and state pollution issues in one fell swoop. When a job is done, the pod is gone, taking any misconfigurations or leftover junk with it.
To set this up, we leaned on Terraform and the gitlab-runner Helm chart. These tools made it straightforward to configure our runners, permissions, cache buckets, and everything else needed to manage the system.
Breaking Up with the Docker Daemon
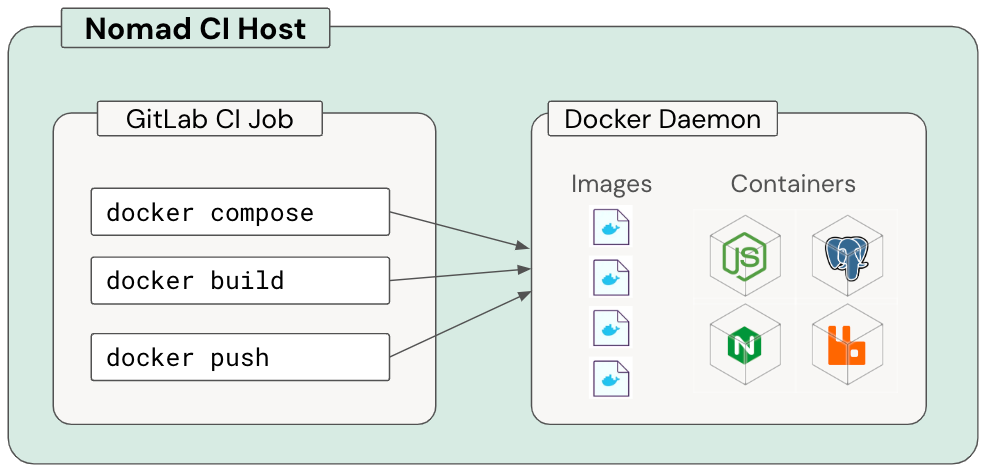
Historically, our CI relied heavily on the host’s Docker daemon via docker compose to spin up services for tests. While convenient for users, jobs sometimes poisoned hosts by failing to clean up after themselves, or they modified shared Docker configs in ways that broke subsequent pipelines running on that host.
Another big problem here was wasted resources and a lack of control of those resources. If a docker compose file spun up multiple containers, they would all share the same resource pool (the host).
Kubernetes gave us the perfect opportunity to cut ties with the Docker daemon. Instead, we fully embraced GitLab Services, which allowed us to define service containers in CI jobs, all managed by Kubernetes, with their resources defined according to the jobs individual needs. And another upside was that GitLab Services worked seamlessly across both Nomad and Kubernetes, letting us migrate in parallel to the larger Kubernetes runner migration.
The Migration Playbook: Moving 600+ Repos Without Chaos
Migrating CI runners is a high-stakes operation. Do it wrong, and you risk breaking pipelines across the company. Here’s the phased approach we took to keep the risks manageable:
-
Start Small We began with a few repositories owned by our team, tagging pipelines to use the new Kubernetes runners while continuing to operate the old Nomad runners. This let us iron out issues in a controlled environment.
-
Expand to Platform-Owned Repos Next, we migrated all repos owned by the Platform team. This phase surfaced edge cases and gave us confidence in the runner architecture and performance.
-
Shared Jobs Migration Then we updated shared jobs (like linting and deployment steps) to use the new runners. This phase alone shifted a significant portion of CI workloads to Kubernetes (saving a ton of money in the process).
-
Mass Migration with Automation Finally, using multi-gitter, we generated migration MRs to update CI tags across hundreds of repositories. Successful pipelines were merged after a few basic safety checks, while failing pipelines flagged teams for manual intervention.
Was it easy? No. Migrating 600+ repositories across dozens of teams was a bit like rebuilding a plane while it’s in the air. We automated where we could but still had to dig in and fix edge cases manually.
Some of the issues we encountered were:
- The usual hardcoded items that needed to be updated, things like ingress urls and other CI dependent services
- We ran into a ton of false positives grokking for docker compose usage in CI, since it was often nested in underlying scripts
- Images built on the fly using docker compose had to instead be pushed/tagged in a new step, while also needing to be rewritten to be compatible as a CI job entrypoint
- We also set up shorter lifecycle policies for these CI-specific images to avoid ballooning costs
- Some pods were OOMing now that we had more granular request/limits, this needed to be tuned for each job’s needs above our default resourcing
- We also took this as a chance to refactor how we auth to AWS, in order to use more granular permissions, the downside was that we had to manually update each job that relies on IAM roles
What About Building Container Images?
One of the thorniest challenges was handling Docker image builds in Kubernetes. Our old approach relied heavily on the Docker daemon, which obviously doesn’t translate well to a Kubernetes-native model. Solving this was a significant project on its own, so much so that we’re dedicating an entire blog post to it.
Check out our next post, where we dive deep into our builder architecture and the lessons we learned there.
Closing Thoughts: A Better CI for a Better Dev Experience
This has measurably increased velocity while bringing costs down significantly (we’ll talk more about cost optimization in the third post in this series).
Through this we’ve doubled the number of concurrent jobs we’re running
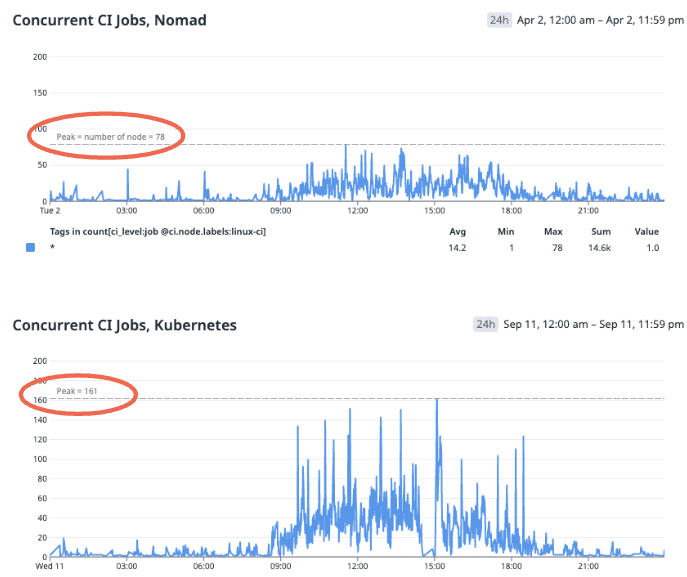
and reduced the average job queue time from 16 seconds down to 2 seconds and the p98 queue time from over 3 minutes to less than 4 seconds!
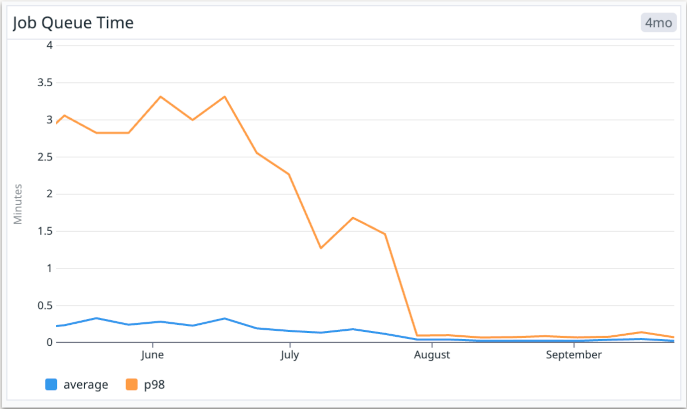
Modernizing CI runners wasn’t just about cutting costs or improving queue times (though those were nice bonuses). It was about building a system that scaled with our engineering needs, reduced toil, increased velocity, and made CI pipelines something developers could trust and rely on.
If your team is looking to overhaul its CI system, we hope this series of posts can provide ideas and learnings to guide you on your journey. Have fun!