In our last post, we discussed why we decided to migrate our continuous integration (CI) infrastructure to Kubernetes. Now, we’re going to tackle the next major challenge: enabling engineers to build and push Docker container images with a solution that is 100% Kubernetes-native. Our solution needed to work seamlessly on Kubernetes, be reliable, and integrate easily with our existing CI/CD workflows. This shift brought unique challenges, unexpected obstacles, and opportunities to explore new ways to improve the developer experience.
Before diving into the technical details, let’s cover how we used to facilitate Docker builds on the previous infrastructure and why we chose to change our approach.
The Past: Building Images on EC2
Before Kubernetes, each CI job was scheduled onto a dedicated EC2 instance and could fully utilize any/all of that node’s resources for its needs. Besides the usual CPU, memory, and disk resources, these nodes also had a local Docker daemon that could be used for building images with simple docker build or docker buildx commands.
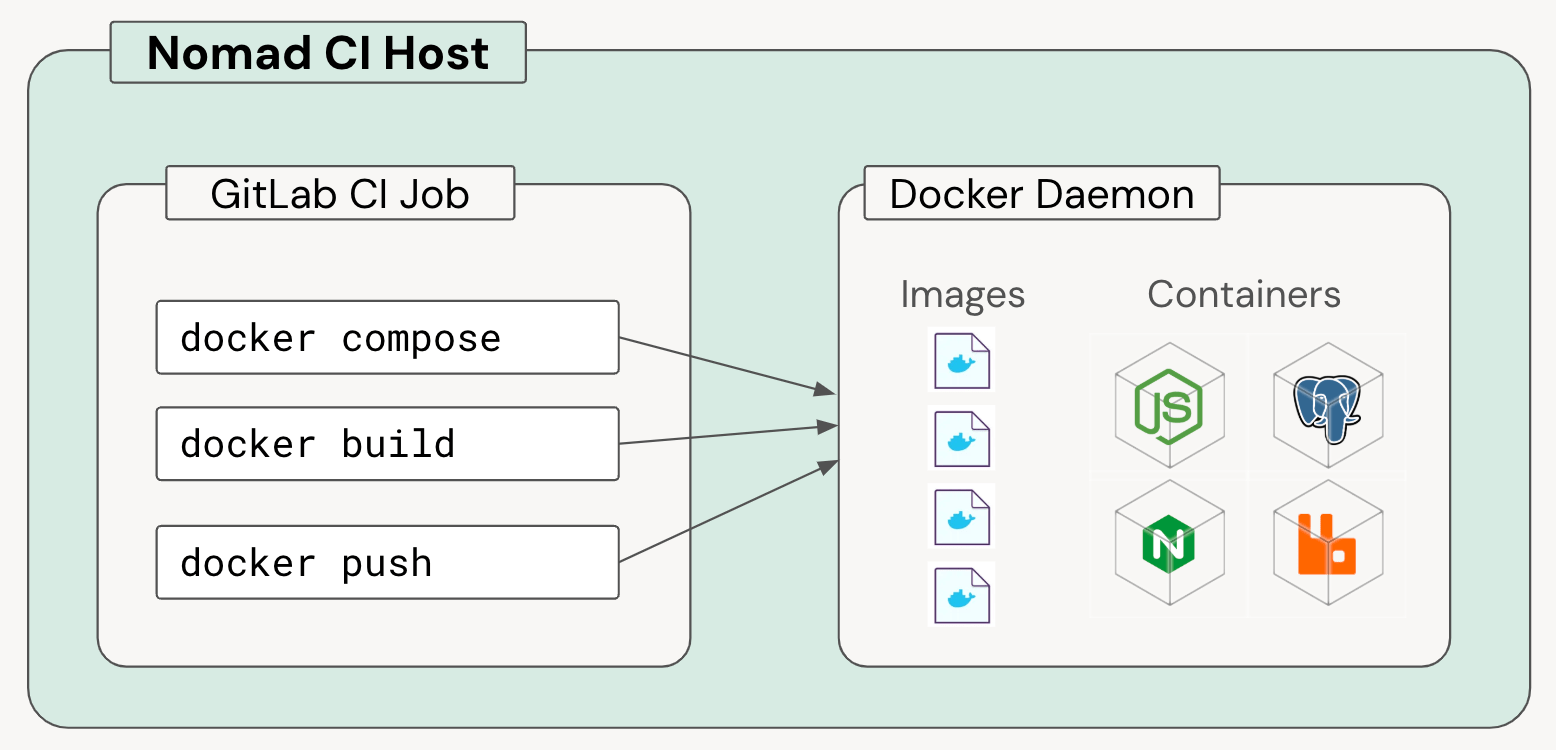
While this setup worked fine most of the time, it had some major limitations:
-
State Pollution: One of the biggest issues was that Docker’s settings could be affected by previous builds. For instance, if a build changed certain global settings (perhaps by running
docker logincommands), it could impact subsequent builds. The absence of true isolation meant that any state left behind by one build could influence the next, which created unpredictability and made troubleshooting difficult. -
Difficult to Maintain: Every aspect of Docker image building was tightly coupled to CI, Nomad, and these EC2 instances. This made it difficult to maintain, troubleshoot, and modify as our needs evolved. Changes were risky which led to a reluctance to make improvements, and so the system became increasingly fragile over time.
-
Lack of Multi-Architecture Support: As we pivoted production workloads to Kubernetes at spot instances, we had a desire to build multi-arch images for both x86 and ARM CPU architectures. Unfortunately, our old setup only supported this via emulation, which caused build times to explode. (We did have a handful of remote builders to support native builds, but these ended up being even more fragile and difficult to manage).
These challenges led us to ask: how can we modernize our CI/CD pipeline to leverage Kubernetes’ strengths and address these persistent issues? We needed a solution that would provide isolation between builds, multi-architecture support, and reduced operational overhead - all within a more dynamic and scalable environment.
Evaluating Options
Knowing we wanted to leverage Kubernetes, we evaluated several options for building container images in our CI environment. We avoided options like Docker-in-Docker (DinD) and exposing the host’s containerd socket due to concerns around security, reliability, and performance. It was important to have build resources managed by Kubernetes in an isolated fashion. We therefore narrowed our choices down to three tools: Buildkit, Podman, and Kaniko.
All three offered the functionality we needed, but after extensive testing, Buildkit emerged as the clear winner for two key reasons:
-
Performance: Buildkit seemed to be significantly faster. In our benchmarks, it built images approximately two or three times faster. This speed improvement was crucial - time saved during CI builds translates directly into increased developer productivity. The faster builds enabled our developers to receive feedback more quickly, which improved the overall development workflow. Buildkit’s ability to parallelize tasks and effectively use caching made a substantial difference in our CI times.
-
Compatibility: Our CI jobs were already using Docker’s
buildxcommand, and remote Buildkit worked seamlessly as a drop-in replacement. This made the migration easier, as we didn’t need to rewrite CI jobs and build definitions. The familiar interface also reduced the learning curve for our engineers, making the transition smoother.
Buildkit Architecture: Kubernetes Driver vs. Remote Driver
After selecting Buildkit, the next decision was how to run it in Kubernetes. There were two main options - a Kubernetes driver that creates builders on-the-fly, and a remote driver that connects to an already-running Buildkit instance.
We ultimately opted to manage Buildkit Deployments ourselves and connect to them with the remote driver. Here’s why:
-
Direct Control: Using the remote driver allowed us to have more direct control over the Buildkit instances. We could fine-tune resource allocations, manage scaling, and monitor performance more effectively.
-
Security: The Kubernetes driver needs the ability to create and manage arbitrary pods in the cluster, a privilege we wanted to avoid granting to the whole CI system. Using the remote driver avoids this because the Buildkit instances are not managed by the
dockerCLI. -
Prior Art: We knew some other organizations were leveraging the remote driver in Kubernetes, which gave us confidence that it was a viable approach. We were able to learn from their experiences and best practices which helped us avoid some pitfalls.
The Pre-Stop Script: Handling Graceful Shutdowns
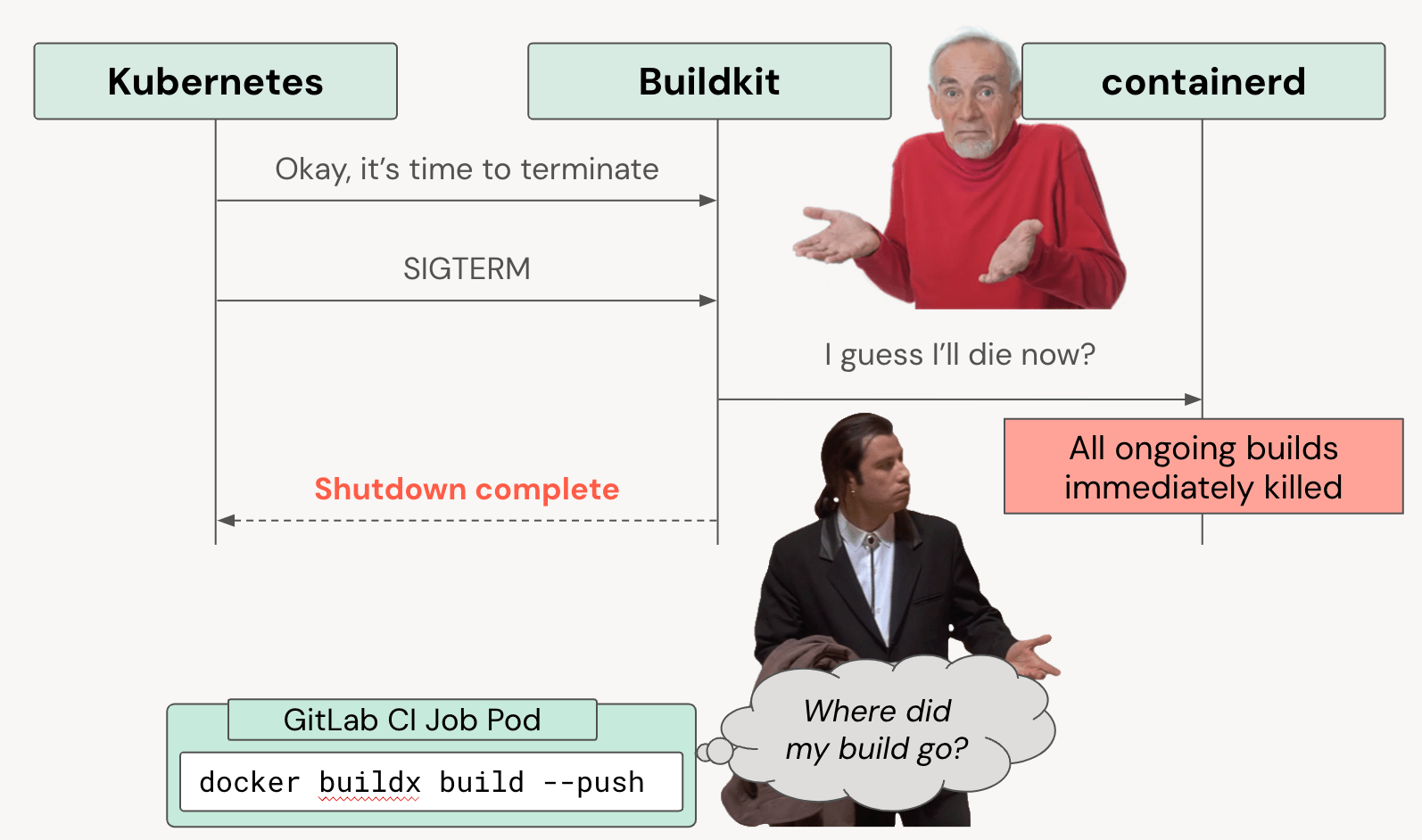
One unexpected problem we encountered relates to how Buildkit handles shutdowns. By default, Buildkit terminates immediately upon receiving a SIGTERM signal from Kubernetes instead of waiting for ongoing builds to finish. This behavior caused issues when Kubernetes scaled down pods during deployments or when autoscaling - sometimes terminating builds in the middle of execution and leaving them incomplete! This was not acceptable for our CI/CD pipelines, as incomplete builds lead to wasted time and developer frustration.
To address this, we implemented this Kubernetes pre-stop hook. The pre-stop script waits for active network connections to drain before allowing Kubernetes to send the SIGTERM signal. This change significantly reduced the number of failed builds caused by premature termination, making our system more reliable.
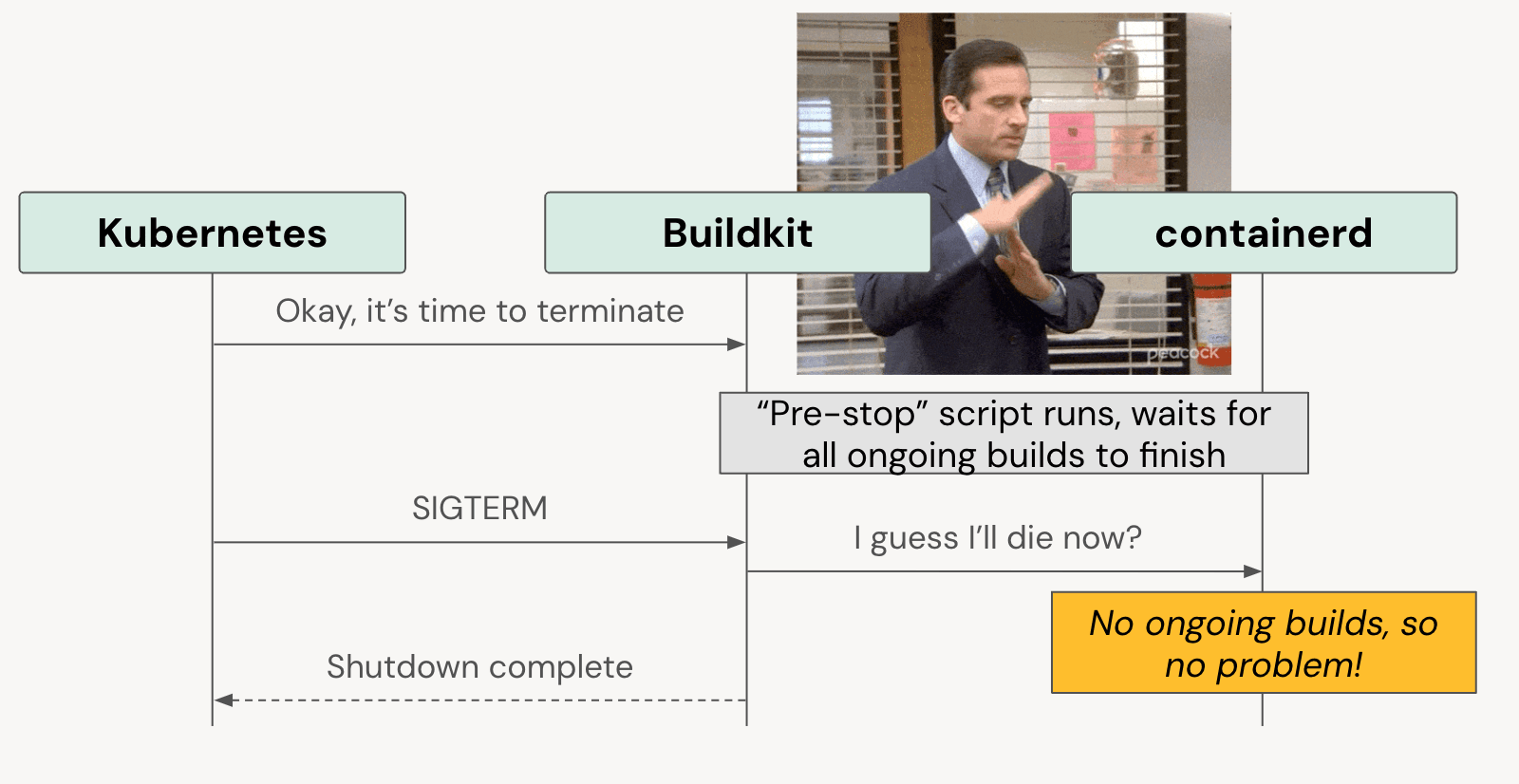
Implementing the pre-stop hook involved some trial and error to determine the appropriate waiting period, and it’s still not perfect, but it ultimately provided a significant boost to build stability. This solution allows Buildkit to complete its work gracefully, ensuring that we maintained the integrity of our build process even during pod terminations.
Reflecting on the New System: Wins, Challenges, and Lessons Learned
Reflecting on our journey, there are several clear wins and other important lessons we learned along the way.
What Went Well
Moving to Buildkit has been a major success in terms of performance! Builds are as fast as ever, and using Kubernetes has allowed us to simplify our infrastructure by eliminating the need for dedicated EC2 hosts. Kubernetes provided us with the scalability we needed, enabling us to add or remove capacity as demand fluctuated. And Buildkit’s support for remote registry-based caching further optimizes our CI build times.
Challenges with Autoscaling
One area where we’re still refining our approach is autoscaling. We’d ideally like to autoscale in real-time based on connection count so that each Buildkit instance is handling exactly one build. Unfortunately the cluster we’re using doesn’t support custom in-cluster metrics just yet, so we’re using CPU usage as a rough proxy. We’re currently erring on the side of having too many (unused) instances to prevent bottlenecks but this is not very cost-efficient. Even if we get autoscaling perfect, there’s still a risk that two builds might schedule to the same Buildkit instance - see the next section for more on this.
Furthermore, we’ve noticed that putting Buildkit behind a ClusterIP Service causes kubeproxy to sometimes prematurely reset TCP connections to pods that are being scaled down - even when the preStop hook hasn’t run yet. We haven’t yet figured out why this happens, but switching to a “headless” Service has allowed us to avoid this problem for now.
What We’d Do Differently
Our decision to run Buildkit as a Kubernetes Deployment + Service has been a mixed bag. Management has been easy, but high reliability has proven elusive. If we could start over, we’d start with a solution that guarantees (by design) that each build gets its own dedicated, ephemeral Buildkit instance that reliably tears down at the end of the build.
The Kubernetes driver for Buildkit partially satisfies this requirement, but it’s not a perfect fit for our needs. We’ll likely need some kind of proxy that intercepts the gRPC connection, spins up an ephemeral Buildkit pod, proxies the request through to that new pod, and then terminates the pod when the build is complete. (There are some other approaches we’ve been considering, but so far this seems like the most promising).
Regardless of how we get there, pivoting to ephemeral instances will finally give us true isolation and even better reliability, which will be a huge win for the engineers who rely on our CI/CD system.
Conclusion
Migrating our Docker image builds from EC2 to Kubernetes has been both challenging and rewarding. We’ve gained speed, flexibility, and a more maintainable CI/CD infrastructure.
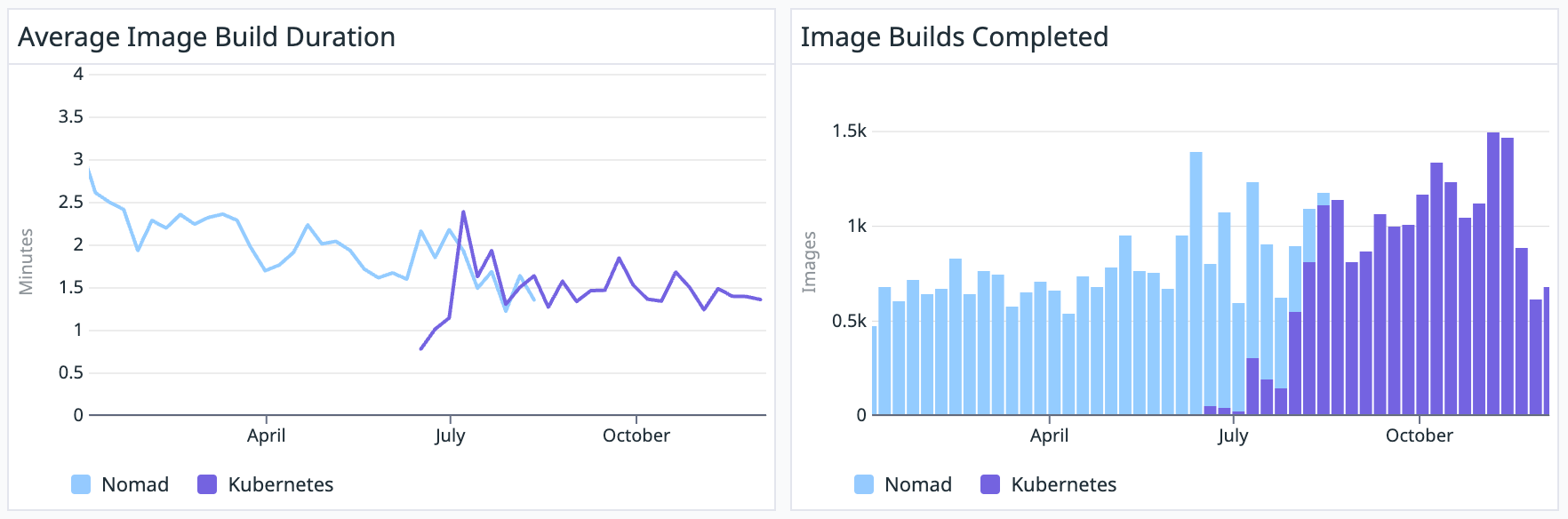
However, it has also been a valuable learning experience - autoscaling, graceful shutdowns, and resource management all required more thought and iteration than we initially anticipated. We found that Kubernetes offered new possibilities for optimizing our builds, but these benefits required a deep understanding of both Kubernetes and our workloads.
We hope that by sharing our experience, we can help others who are on a similar path. If you’re considering moving your CI builds to Kubernetes, our advice is to go for it - but be prepared for some unexpected challenges along the way. The benefits are real, but they come with complexities that require careful planning and an ongoing commitment to refinement.
What’s Next?
Stay tuned for the next post in this series, where we’ll explore how we tackled artifact storage and caching in our new Kubernetes-based CI/CD system. We’ll dive into the strategies we used to optimize artifact retrieval and share some insights into how we managed to further improve the efficiency and reliability of our CI/CD workflows.