This week at SeatGeek, we are saying a fond farewell to four fantastic co-op students from the University of Waterloo. This was our first time participating in Waterloo’s work partnership program, and we are thrilled with how it has gone.
There’s always more to be done at SeatGeek, growing as fast as we are, and working with the co-op students from Waterloo let us conquer new projects while connecting with the academic world and exposing our company to a talented group of students.
In this post, we want to highlight the contributions of our co-ops and let them describe what they did for SeatGeek.
Erin Yang - Data Team
I worked on the Data Science team. At SeatGeek, the data scientists also perform the data engineering tasks. We collect data and maintain our production services in addition to harnessing the data for the company. I was able to blend well into the team, contributing to both responsibilities. I took on initiatives to reduce tech debt, learned Apache Spark and wrote production EMR jobs.
I also worked on two larger research projects using the data already in our warehouses. Both gave me the chance to flex my analytical skills, proposing performance metrics and predicting business outcomes. In this post, I will only discuss my work on stadium-level pricing recommendations.
For individuals looking to sell tickets on our SeatGeek, we recommend listing prices based on historical data and other listings for the event in question. I investigated what we could learn by trying to recommend listing prices to a venue or promoter organizing a new event. This would mean recommending prices for all the seats in the venue at once and using only historical data as there would be no existing listings to compare against.
I have built a system that will give price recommendations for each seat based on historical secondary market prices for similar events at the same venue. I trained a statistical model using secondary transactions records, considering the variation in all-in price (prices with fees), 2D and 3D seat locations, event types, and more event-level features. As long as we have sufficient transactions for a section in the venue’s map, then we are able to generate price distribution of all seats in this section.
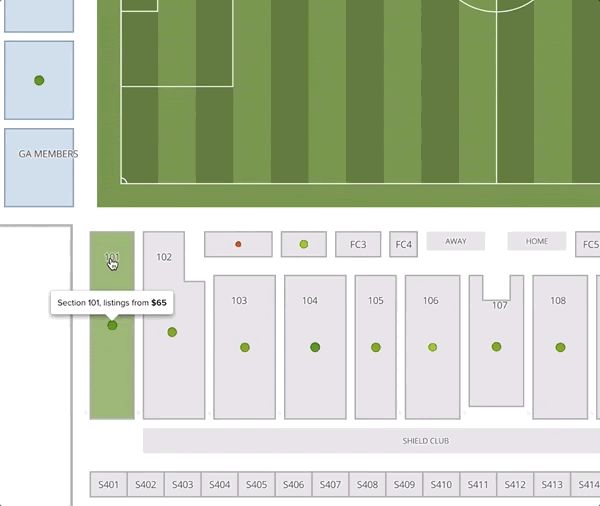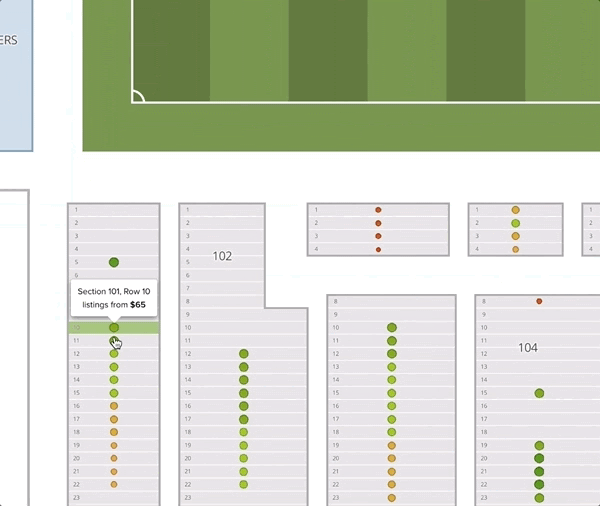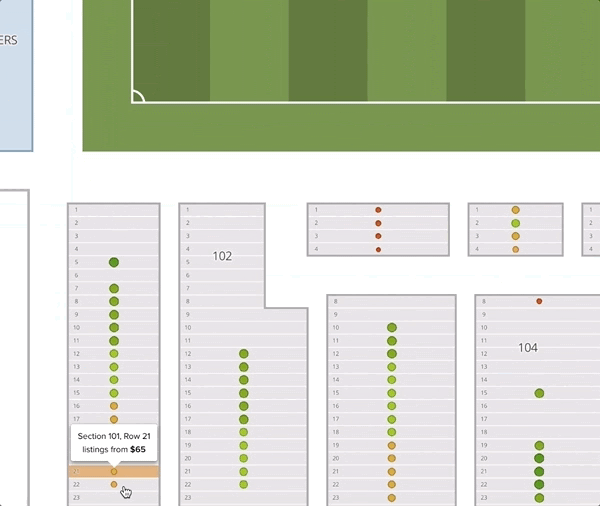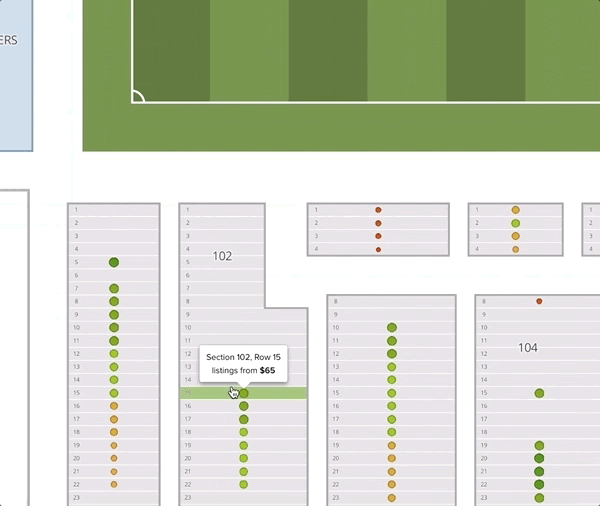
The predictions offer us some insight into how an optimally priced event might look. Here we see the ideal prices (normalized by event) for 3 large American venues (the darker seats are cheaper):
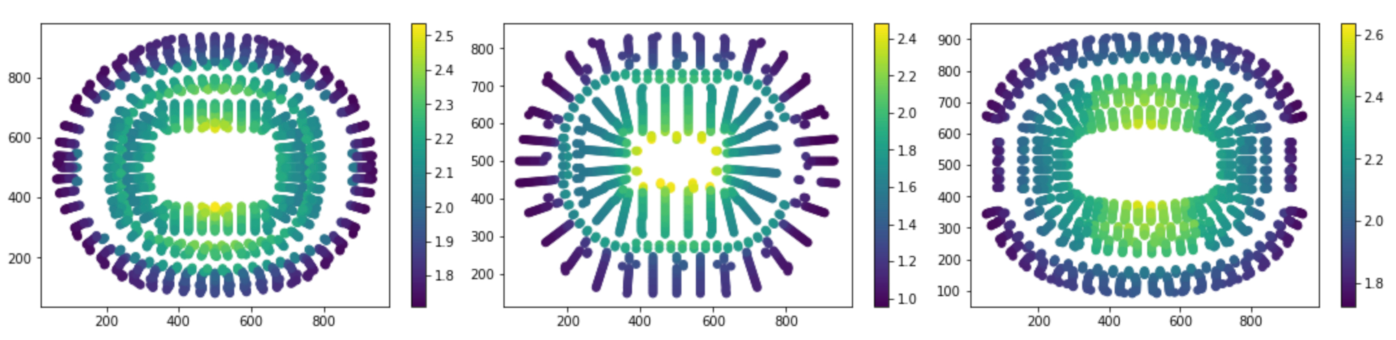
One thing worth noticing is that the recommended prices within a section decrease as the seat gets further from the field. Although this seems intuitive, it goes against common practice. Often venues or promoters will price all the seats in a given section (and adjacent sections) uniformly. In this example map, we give all the tickets in sections 101 and 102 the price of $65. We can see that the deal quality drops off as we move back in the section.
It is not easy to contribute to a company as a data scientist in only four months. Nevertheless, I had an incredible time working here. I received a significant amount of guidance and support from my team members, and was able to test ideas and improve our production services.
Hobin Kang - Data Team
During my time at SeatGeek I worked with the data science team focusing on projects related to Search Engine Marketing (SEM). Working on SEM required me to work on a variety of levels in the Data Science stack, ranging from tasks such as optimizing SQL queries for daily revenue per ad click predictions to analyzing onsale data. Working at SeatGeek gave me a better perspective on what the data science process is and how crucial data engineering groundwork is for a successful data science project. All successful data science products start with a strong data pipeline and infrastructure.
Working in SEM means interacting with complicated domain-specific problems and data sources. Our team is working on optimizing SEM ad spend by predicting the value of clicks on our SEM ads, but that work relies on a complicated network of ETL tasks (Extract, Transform, Load). I mainly worked on ETL for SEM tables, adding new data sources and centralizing query logic. One of the tools I was able to learn when performing ETL work was Luigi. Luigi is a python module that helps engineers build complex pipelines while handling dependency resolution and workflow management. Some SEM jobs have strict upstream dependencies, making this a perfect use case for Luigi. Working first hand with ETL jobs in the data warehouse, I was able to familiarize myself with the Luigi framework.
After writing a complex query that follows many upstream dependencies from AdWords, inventory and sales tables in our data warehouse, I understood how complex a productionized Data Science project can get. This internship helped me understand the importance of data engineering. I also realized that modeling is useless without having the right data in the right places first. Working from the ground up gave me a new perspective on how every part of the stack falls together to create a cohesive and concise project.
Sam Lee - Product Team
At SeatGeek, I was a member of the Discovery team. The focus of this group is to help users find the perfect tickets to the perfect event. We focus on building user-facing features, but shipping these features almost always requires significant backend development.
I worked primarily on two projects: improving discoverability of parking passes and adding song previews to the iOS browse screen. Both projects were in line with the Discovery team’s mission, but in slightly different ways. The improvement to parking pass search results helps users find tickets they are already looking for, while the song previews help users discover artists they might not be familiar with.
When we list parking passes, we make separate parking-specific event pages so that our users can see maps of the lots just as they would see seating charts. These events can be tricky to find though, so we worked to pair parking events with their parent events, surfacing both in relevant searches. This increased visibility further advertises our in-app parking events to our users and, like the track previews, keeps the experience within the SeatGeek app.
Our song previews project helps introduce users to new performers. In the past, if a user encountered a new artist while browsing events on SeatGeek, they would have to go elsewhere to learn about the performer, maybe listen to their music, and then return back to our app again to look at tickets. Now, with a single tap, users can play top tracks from featured artists while continuing to browse upcoming events. My contribution involved integrating data and functionality from Spotify in to our internal API payloads which enables our frontend to play tracks.
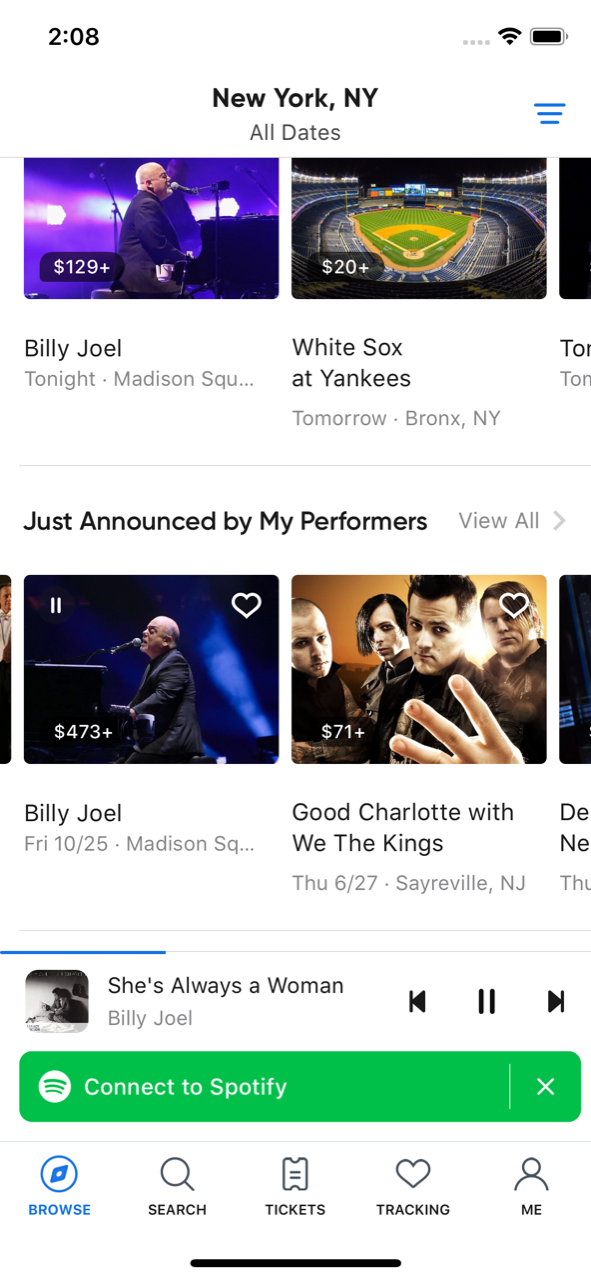
Both of these projects spanned multiple weeks, represented real gains for the business, and improved our users’ experience. They were both complicated and difficult, spanning five different microservice repositories each with an entirely unique and intricate tech stack. I learned how to update ElasticSearch clusters, coordinate microservices using Google Protocol Buffers, and leverage Redis caches all while writing my first Python and Golang code, each with their respective frameworks, ORM’s, and paradigms.
At SeatGeek, I was privileged with an internship with unorthodox qualities: accountability, responsibility, and ownership. The projects I worked on made a direct difference to our users. I was not an intern during my time at SeatGeek; I was a Software Engineer for four months.
Tyler Lam - Product Team
I worked on SeatGeek’s Growth team, a cross-functional group of marketers and engineers focused on helping our product reach more users. My team’s work ranges from page speed improvements and paid search algorithms to design changes and promotions.
For my main project, I worked on enriching our theater pages. We had two motivating factors that made this improvement a priority.
The first, as is often the case, was a desire to improve the user experience. Historically, our pages simply listed the upcoming events, as we do for sports teams or touring artists. For users trying to decide what shows to see, this wasn’t the most helpful view. These users would have to navigate away from our site to get information that would help them to choose a show.
The new, enhanced page includes a brief introduction to the production, logistical information about the performance (run-time, location, age restrictions) and a selection of critic reviews. We even show award wins and nominations for the shows that earn them! If these specs aren’t enough, the user can get a preview of the show by browsing through a photo gallery or watching the video trailer.
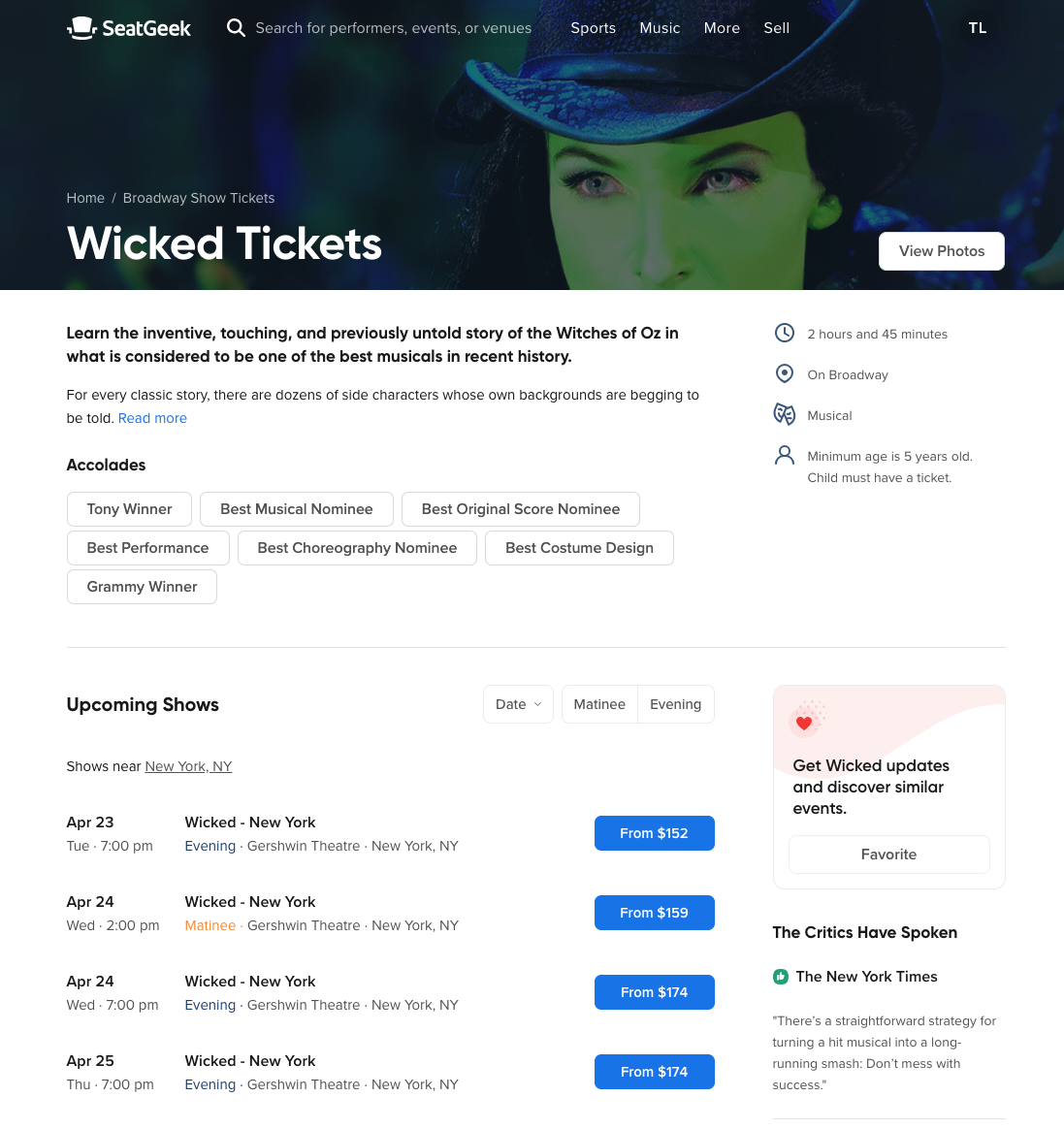
The second motivation for these improvements centers on search engine rankings. A huge amount of our traffic comes from search results. For the Growth team, rising up a search page means the chance to introduce new users to SeatGeek. Enriching our theater pages with relevant content and links improves our search result scores and helps us show our improved pages to a larger audience. These new pages benefit SeatGeek from a business perspective and provide a better user experience.
Throughout my term with SeatGeek I sharpened my front end react skills and learned how to effectively collaborate with designers. It was rewarding to work on this project from start to finish and see it live in production, especially in the short time span of 4 months. The product team at SeatGeek provided many opportunities for their interns to make an impact.