But in the last month of the year, we’re lucky to add one more accolade to the list. It’s an important one to us because it’s about our team. We’re thrilled that for the second straight year, SeatGeek is on Glassdoor’s list of Best Places to Work in 2018.
Something noteworthy about this award is that there was no self-nomination process. The scores are based on SeatGeek employee feedback given voluntarily (and anonymously) on Glassdoor over the past year. It’s humbling to make the list two years in a row – there were only nine other companies in the US that did so.
The fact that SeatGeek is a great place to work is one of the things we’re most proud of as a company. Working here has its perks: SeatGeek’s social calendar is full of parties and retreats, our kitchen pantry is on par with that of a five-star restaurant, and our monthly ticket perk helps employees attend their favorite live events.
But what really makes this a place to do great work – and have fun – is less tangible. SeatGeek is is an amazing place to contribute, grow, and build something special. The team believes in the power of live entertainment to make people happier, and there is a genuine passion for building a product that enables great experiences. The environment here encourages that, and the reviews reflect it.
As a company, we have some lofty goals for 2018 and beyond. We operate in an industry that has long been overdue for a fundamental shift, and SeatGeek is a catalyst for change in ticketing. We’ll stay focused on launching great products, partnering with amazing clients, and building out a distribution network for ticketing across the internet.
But one of our most important goals is to continue to be a fixture on awards lists like Glassdoor’s. As our team continues to grow, we’re fortunate to have found people that continue to embody SeatGeek’s core values. The people at SeatGeek that bring these values to life are our most valuable asset, and are what we hear about most often when employees talk about their favorite parts of working here.
If this sounds interesting to you, come work with us at SeatGeek! We have a number of roles open across engineering, marketing, business development, and more.
Cultural diversity is an important ingredient in creativity. At the tip of our process and teamwork, we leverage the different ways we use the internet and user interfaces to help us craft a well-rounded product and user experience. While cultural diversity can often be taken for granted being in New York City (where we call home, and can arguably be considered the “melting pot of the world”) we at times will hire extraordinary talent, no matter which city they call home.
I’m a Senior Director of Engineering at SeatGeek, and my team consists of engineers from 5 countries across 3 continents: North America, Europe and Africa. My situation is not at all unique in the engineering industry. Distributed team management is often a challenge many organizations face as they scale and sometimes hire extraordinary talent outside of their borders.
In my career, I’ve been involved in rapid scale, with remote teams, across many timezones and different working cultures. This type of scale and distributed team organization would not have been successful without travel, regular facetime, lots of communication, good processes and supporting software. So, naturally, one of the first things after I started at SeatGeek and joined my team was book flights to Copenhagen to meet some of them.
Now, I realize there are very good blog posts, books and talks about distributed team management and I certainly don’t have all the answers (I read those blogs and books, too!), but I felt it would be interesting to you to hear about my trip to Copenhagen, and share with you where we learned to be better with our distributed team.
Here’s what went down:
Saturday & Sunday - Day 1 & 2 - Copenhagen:
It was great being back in Scandinavia (I used to live in Stockholm, Sweden). The weather was cool, the food was delicious (fish, pickled everything, breads, cheeses…) and the beer (Mikkeller ftw) was plentiful.
If you ever get out to Copenhagen, here’s my hit list:
The northern neighborhoods of Copenhagen are tree lined, quaint and picturesque. Easy to get lost and found again.
Monday - Day 3 - Meets and Greets:
One of the immediate thoughts I had walking into workspaces is that it felt just as I remembered what any good Scandinavian workspace should be. Lots of plants, the low northern sunlight creeping through some shades, the smell of coffee, subtle music playing in the background… the atmosphere was very familiar. The floor the workspace is on is packed with other Danish tech startups. Some companies were game makers, others were building PaaS software, and there was everything in between. This workspace definitely had the better corner views, though. Great vibes all round, I loved being surrounded by other technologists and watching the Danish startup culture in full flight.
Day Agenda:
SeatGeek news, updates & open conversation
Distributed Team Effectiveness (Open Conversation)
1:1’s!
Dinner and beer.
SeatGeek news, updates & open conversation:
We sat around the workspaces in an open conversation and discussed things that have been going on in the SeatGeek offices of New York. As a distributed team you can sometimes miss out on the regular news updates that you can get at the HQ. I learned that we can be better at sharing milestones and regular news, which at first may not seem mission critical, but really are vital to building the SeatGeek culture across the pond.
Distributed Team Effectiveness:
This was a great discussion around how we can be better working in a distributed team model. Hot topics like being social, communication and process and tools were discussed at length.
Being Social:
While we don’t follow “Capital A” agile strictly speaking, we do conduct the typical scrum ceremonies. I learned that we can be better in our standups. Given that standups are the one time of the day that the whole team is together, we should give our best effort to make it as effective and useful as possible. One idea was that since we are a little loose in our agile ceremonies, given the distributed nature of the team we thought that being a little more social in those meetings would help grow relationships and allow us time to bond. Having a few offtopic points about our weekends, or hobbies are a great way to learn about each other. This has been a great tweak to our process and I know there is some great back chatter amongst the team. We do our best to stay the course during the stand up, and enjoy some light chatter afterwards.
We also decided to have an “always open” Google hangout for people to join and chat like a party line. This has proven to be a great idea and a lot of fun!
Communication:
We felt that the communication channels we use should be consistent. Sometimes an issue will be discussed in a private chat and not in the team chat, or sometimes an issue is discussed in a ticket and not updated in any chat channels. We agreed to be better at communication and work to moving the conversation into a single channel, and to use our tools to help communication be more visible to the wider team.
Process and tools:
We recognized that there needs to be a little more planning in place to avoid being blocked by the 6 hour time gap between Copenhagen, Africa and NY being online. Let’s use our tools to understand the bottlenecks and try to resolve them and any blockers before EOD.
We have been using Geekbot as our stand-up / stand-down bot in Slack. It’s working really well for us.
Dinner and beer:
One of our engineers, having just returned from a vacation to Croatia, decided to take all of us to a Croatian restaurant in the center of Copenhagen - Restaurant Dubrovnik (don’t worry, I got my fair share of Danish cuisine in). We ate some delicious Croatian fare and started to get into the nitty-gritty of our work.
It was getting a little warm in that restaurant, so we decided to move to a craft beer bar called Taphouse. Taphouse is a pretty cool bar, owned by a Danish engineer with a love for beer and tech (perfect!). It had digital displays for what beers are currently on tap and the lights of the bar would flash when a new keg got hooked up – us geeks loved that. Great selection of beer!
Our discussions went long into the night, and without realizing it an hour had passed with empty glasses due to rich conversation. We decided to call it a night and pick things up in the morning.
Tuesday - Day 4 - Wrap up:
We were off to an early start and continued our conversations around being distributed, our engineering duties and plans for the future. A quick taxi ride to the airport and I was back on my way to NYC… a whirlwind trip but the facetime is invaluable and sets grounds for a great long lasting relationship.
In summary:
Overall, traveling, whether you’re going there or coming here is going to be the catalyst for a great engineering culture with distributed teams. Some of my best friendships were forged through working in a distributed team. I have been on the other side of the fence (living in Stockholm and working for a NYC-based company) and I understand that it takes extra effort to be effective and optimized. If you encourage a great communication culture, and use good processes, and travel, you’re already heading in the right direction.
Karl Stanton is a Senior Director of Engineering at SeatGeek with a core focus on technical leadership, career development and distributed team management.
Welcome to SeatGeek Employee Spotlights – an opportunity to meet the fantastic folks on our world-class team.
By day, we’re a group of talented developers, designers, marketers, and businessfolk working together to build something new and different. But we are also fans and live event junkies of every kind: diehard sports fans, passionate concert-goers, sophisticated theater enthusiasts, and more. From our lives outside the office and within, we all have interesting stories to tell.
Up next: Lily Dai from our finance team!
Where were you born?
Los Angeles
Have you always lived in NYC?
No, I just moved from LA six months ago.
Where did you go to school?
I went to the University of Southern California and studied Business and Film with a double major in Accounting
Any funny roommate or apartment stories in NYC? Feels like everyone has at least one…
We were friends on Facebook, but we never talked until I reached out to see if she needed a roommate. Can’t think of any funny stories, but we once had 12 pints of Halo Top in the freezer. I called it the “Juice Cleanse”.
How would your friends describe you in 3 words?
Goofy, perceptive, adventurous
Best project you’ve worked on at SeatGeek
We’re currently redoing our forecast for the next 18 months. We’re talking to the product, marketing, and recruiting teams and learning what their needs are. I’m diving a lot deeper into our business. (I know all the secrets.)
What is your dream project to work on at SeatGeek?
My dream project would be to do a deep dive into our snack inventory and find out what’s the most popular. Personally, some of the protein bars taste like chalk, so figuring out which can go and what new ones we can get.
3 “fun facts” about yourself that people would be surprised to know
* You can pour 5 cans of any beverage into a frisbee disk, and I can drink it very quickly.
* I fixed cars with my dad for about 10 years. If I’m ever stranded, I can fix the car.
* I’ve taught my kitten to fetch.
Favorite place(s) to hang out in NYC
Prospect Park. I’ve been there about 30 times, and I still get lost almost every time. I also love that NYC has a bunch of queer spaces to hang out.
Best vacation you’ve ever taken
My post-college trip with my friends to East Asia. We went to six countries. We had island lifestyle and ancient temples. It was a great way to close out college plus everything was a dollar. We had an oceanfront hotel room for 50 bucks.
Favorite SeatGeek snack
Peanut butter pretzels
Why do you love SeatGeek?
Besides our business model, I love our culture. We had a pride themed happy hour. I almost teared up at how supportive everyone was of our LGBTQ co-workers. It was the perfect example of how supportive and open-minded everyone is here.
Favorite part of the office?
I love the pods in the lounge. They’re super comfy, and you could take a nap if you wanted to while watching the people at Blink work out.
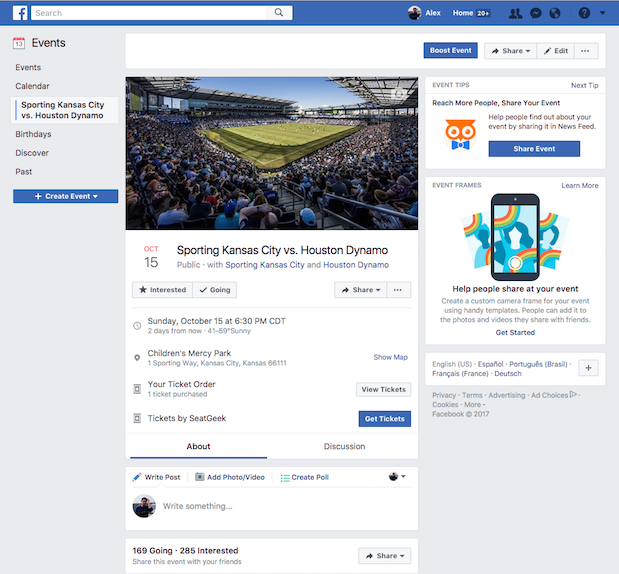
We launched our primary ticketing platform a year ago with one overarching goal: to get more fans to live events. Through our open API approach, an open ticketing ecosystem will create opportunities to increase distribution, empower teams and artists to sell on the platforms of their choice, and eliminate fraud through a process of barcode verification. At the end of the day, our goal is to increase discovery of live events by using the power of the open web, putting tickets where fans are already spending time online.
Today we’re taking a major step toward that goal, and are thrilled to add Facebook as a distribution partner for SeatGeek. As the world’s largest social media network, Facebook powers an incredible amount of delightful discovery of information for their users, whether it is through a news post, long-lost childhood friend, or adorable cat video. We’re stoked to be able to add a piece of the live entertainment world to that.
SeatGeek primary ticketing client Sporting Kansas City will be the first to utilize this new partnership, selling tickets directly to fans through Facebook. We’re excited to expand this partnership to more SeatGeek partners in 2018 as the industry moves toward openness.
While we have already seen great success with SeatGeek distribution partners such as Gametime and TicketNetwork, adding the world’s largest social network to the mix is a game changer for both clients and fans. Exposing inventory directly to fans on Facebook will make for a seamless shopping experience, resulting in more tickets sold, more events attended, and most importantly, more fun for fans.
Our Facebook partnership comes at an exciting time for SeatGeek, coinciding with the recent announcement of SeatGeek Enterprise, our powerful stack of primary ticketing services solidified into one brand. SeatGeek Enterprise promotes our vision of an open ticketing world, in which venues and rightsholders enjoy unprecedented flexibility, transparency and monetization potential. Our open distribution approach is a crucial piece of the SeatGeek Enterprise offering and one of the most important ways we are empowering rightsholders and putting more control in the hands of teams and venues.
We’re thrilled for fans to begin to see this partnership in action in their newsfeeds, as we continue to put the fan first in an industry that for too long has been more than happy to sit on its hands when it comes to innovation.
Welcome to SeatGeek Employee Spotlights – an opportunity to meet the fantastic folks on our world-class team.
By day, we’re a group of talented developers, designers, marketers, and businessfolk working together to build something new and different. But we are also fans and live event junkies of every kind: diehard sports fans, passionate concert-goers, sophisticated theater enthusiasts, and more. From our lives outside the office and within, we all have interesting stories to tell.
Up next: Erin Elsham, on our People Ops team!
Where were you born?
Toledo, Ohio. Well, I was born there – we moved to Iowa after a year, then to Kansas. My dad worked in the agriculture business, so we moved around the midwest with him a bit.
Have you always lived in NYC?
Nope! I packed 2 suitcases and bought a one-way ticket from Kansas City 6 years ago.
It’s kind of funny – I went to college in Kansas as well. I was the odd one out of my really close friends and went to Kansas State, even though I was a Kansas University fan growing up, so that was a funny rivalry thing. New York City, for some reason, draws a lot of Kansas people – there are a couple of well-known KU bars here, and I have some friends from growing up who had moved out here right after school. I went to visit one of my best friends and her husband who were living in Williamsburg, and at the time I had just gotten out of school and was bored with what i was doing, so I moved out there. They were nice to let me stay with them for a bit. I literally packed two suitcases and moved, and six years later here I am.
Where did you go to school?
Kansas State University, Go Jayhawks! Oh wait, that’s KU (I grew up a KU fan). That’s the thing - I went to school at K-State, but was not into K-State sports.
Any funny roommate or apartment stories in NYC? Feels like everyone has at least one…
I’ve always lived in WIlliamsburg, and once we found an apartment with a backyard, we decided we’d stay there for a while. Because it’s a shared backyard, we’re friends with all of the tenants now, so if there’s ever a backyard party or barbecue, everyone is invited. One time, a friend of a friend who does photo shoots and works with modeling agencies asked if she could do a shoot back there. They brought in a really fancy model and props that totally confused the neighborhood, it was pretty funny.
How would your friends describe you in 3 words?
Full of surprises!
I’ve been told that I’m like a stealth bomber – I’m pretty quiet for the most part, but I listen to everything, so I always kind of know what’s going on. Even with friends and family, I’ll know what’s going on and plan something that will surprise them in one way or another. For example, my boyfriend’s 30th birthday: he really likes Wet Hot American Summer, so I planned a themed party in our backyard and made everyone wear 70s camp gear. He had no idea. Also, the SeatGeek portraits – nobody knew that was coming. I like surprising people.
Best project you’ve worked on at SeatGeek?
There are a ton! I love to show off how fun we are as a company, so employee portraits and Life@SeatGeek Instagram account are the top!
What is your dream project to work on at SeatGeek?
Workation was a blast planning last year and I can’t wait to plan an even better event for this year. It’s a huge challenge planning an event for 150 people, but I’ve got some good ideas and am super excited.
What are three “fun facts” about yourself that people would be surprised to know? I’m an aerialist. I perform trapeze in seasonal circus cabarets in Brooklyn, wear funky costumes and fly in the air – think that’s the most fun fact I’ve got.
It’s all volunteer, and I choose my own songs and make the costumes I wear during shows. I’ve been doing it for about 5 and a half years at the same circus school in Williamsburg, am really close with my teacher and have made some amazing friends there.
Favorite place(s) to hang out in NYC?
Backyards and rooftops – there’s nothing better than living in the borough with the view! There are a lot of cool places, but they’re always too crowded – once you find someone with rooftop access, you’ve made it. The beach is fun to go to as well – I usually try Rockaway.
Best vacation you’ve ever taken?
So far, my first “real” vacation as an adult with no plans and no weddings was Puerto Rico with my fiance three years ago. I’ve been a bridesmaid like seven times, and have had a wedding almost every single year, so I haven’t taken a lot of vacations because it was all weddings for a while. Puerto Rico is great – it’s cheap, fun, and the water is clear.
Favorite SeatGeek snack?
Eggs? Do those count? Is that weird?
Why do you love SeatGeek?
It’s the people – everyone’s cool. They’re all so amazing, friendly and welcoming. So many smiles. There is not a single person I don’t feel like I could talk to.
Favorite part of the new office?
SG Portrait wall – sorry, I’m biased! That was the most fun I’ve had on a project. I had to be secretive about it (which I love), and we hired an outside designer for it and worked with them to get the details right and continue to work together for SG 1-year anniversaries!
Builds a service with docker and caches the intermediate stages
At SeatGeek we use Multi-stage Dockerfiles to build the container images
that we deploy to production. We have found them to be a great and simple way of building projects with dependencies in different languages or tools.
If you are not familiar with multi-stage Dockerfiles, we recommend you take a look at this blog post.
In our first days of using them in our build pipeline, we found a few shortcomings that were making our deploys take longer than they should have. We traced
these shortcomings to a missing key feature: It is not possible to carry statically generated cache files from one build to another
once certain source files in the project change.
For example when building our frontend pipeline we have to invoke yarn first to get all the npm packages. But this command can only be executed after
adding the yarn.lock and package.json files to the Docker container. Because of the nature of how Docker caching works, this meant that each time those
files are modified, the node_modules folder cached in previous built was also trashed. As you may already know, building that folder from scratch is not
a cheap operation.
Here’s an example that illustrates the issue.
Imagine you create a generic Dockerfile for building node projects
1234567891011121314
FROM nodejs
RUN apt-get install nodejs yarn
WORKDIR /app
# Whenever this image is used execute these triggers
ONBUILD ADD package.json yarn.lock .
# Dowanload npm packages
ONBUILD RUN yarn
# Build the assets pipeline
ONBUILD RUN yarn run dist
We can now build and tag a Docker image with for building yarn based projects
1
docker build -t nodejs-build .
The tagged image can be used in a generic way like this:
1234567891011
# Automatically build yarn dependenciesFROM nodejs-build as nodedeps
# Build the final container imageFROM scratch
# Copy the generated app.js from yarn run distCOPY --from=nodedeps /app/app.js .
# Rest of the Dockerfile...
So far so good, we have build a pretty lean docker image that discards the node_modules
folder and only keeps the final artifact. For example a set of js bundles from a React application.
It’s also very fast to build! This is because each individual step is cleverly cached by Docker during
the build processes. That is, as long as none of the steps or files used in the step have changed.
And that’s exactly where the problem is: Whenever the package.json or yarn.lock files change, Docker
will trash all the files in node_modules directory as well as the cached yarn packages and will start downloading
from scratch, linking and building every single dependency.
That’s far from ideal, as it takes significant time to rebuild all dependencies. What if we could make a change to the
process so that changes to those files do not bust the yarn cache? It turns out we can!
Enter docker-build-cacher`
We have built a slim utility that helps overcome the problem by providing a way to build the Dockerfile
and cache all of the intermediate stages. On subsequent builds, it will make sure that the static cache
files that were generated during previous builds will also be present.
The effect it has should be obvious: your builds will be consistently fast, at the cost of a bit of extra disk space.
Building and caching is done in separate steps. The first step is a replacement for the docker build command and
the second step is the cache persisting phase.
123456
export APP_NAME=fancyapp
export GIT_BRANCH=master # Used to internally tag cache artifactsexport DOCKER_TAG=fancyapp:latest
docker-build-cacher build # This will build the docker filedocker-build-cacher cache # This will cache each of the stage results separately
How It Works
The docker-build-cacher tool works by parsing the Dockerfile and extracting COPY or ADD instructions nested
inside ONBUILD for each of the stages found in the file.
It will compare the source files present in such COPY or ADD instructions to check for changes. If it detects changes,
it rewrites the Dockerfile on the fly, such that FROM directives in each of the stages use the locally cached images instead
of the original base image.
The effect this FROM swap has is that disk state for the image is preserved between builds.
Disaster Recovery and Configuration Management for Consul and Vault
This post is the first of a bonus series on tooling for the Hashi-stack - Consul, Nomad, Vault. We also recommend our previous series on using Vault in production.
Configuration Management for your Configuration
In our initial Vault rollout, one pain-point we quickly came across was managing Consul and Vault configuration. We use both Hashicorp tools for managing secrets and access control across our entire infrastructure, and knowing what configuration was setup where in each cluster is quite critical. On top of this, disaster recovery quickly became an issue we knew we needed to tackle before a more broad roll-out.
One of our Systems Engineers started looking at what our needs were in regards to properly managing Consul and Vault configuration, and came up with a wonderful workflow through the use of a tool we like to call hashi-helper. We use hashi-helper internally to manage multiple clusters in different environments via a git repository that contains our canonical configuration. It is now pretty trivial for us to:
Standup a vault cluster using our normal provisioning toolchain.
Unseal vault via gpg key via the normal vault tooling, or keybase via hashi-helper vault-unseal-keybase.
Provision mounts, policies, and secrets using hashi-helper vault-push-all.
Provision custom registered consul services via hashi-helper consul-push-services.
Manage all of our configuration via either blackbox gpg-encrypted files or AWS KMS encryption through tooling such as sm.
Example Workflow
For those curious about what a typical workflow might look like, the following directory structure may be suitable for a typical organization with a Consul/Vault cluster per-environment:
/${env}/apps/${app}.hcl (encrypted) Vault secrets for an application in a specific environment.
/${env}/auth/${name}.hcl (encrypted) Vault auth backends for an specific environment ${env}.
/${env}/consul_services/${type}.hcl (cleartext) List of static Consul services that should be made available in an specific environment ${env}.
/${env}/databases/${name}/_mount.hcl (encrypted) Vault secret backend configuration for an specific mount ${name} in ${env}.
/${env}/databases/${name}/*.hcl (cleartext) Vault secret backend configuration for a specific Vault role belonging to mount ${name} in ${env}.
Here is an example for managing Vault Secrets:
12345678910111213141516171819
# environment name must match the directory name
environment "production" {
# application name must match the file name
application "XXXX" {
# Vault policy granting any user with policy XXXX-read-only read+list access to all secrets
policy "XXXX-read-only" {
path "secret/XXXX/*" {
capabilities = ["read", "list"]
}
}
# an sample secret, will be written to secrets/XXXX/API_URL in Vault
secret "API_URL" {
value = "http://localhost:8181"
}
}
}
We believe that modern technology can be a force for good in live entertainment. That’s why we created SeatGeek Open – a platform which enables teams, artists, and fans to buy and sell tickets across the open web. Openness means harnessing the power of the internet to create better experiences.
In order to launch SeatGeek Open last August, we needed to find a partner that shared our vision, and whose powerful box office technology would enable a true API-driven entertainment platform. We did an exhaustive worldwide search, but in the end the selection of Israel-based TopTix was remarkably clear and unequivocal. They brought unprecedented technology and incredible talent to SeatGeek Open.
Today, we’re over-the-moon excited to announce that TopTix is joining SeatGeek.
TopTix was started in 2000 in Karmiel, Israel by two remarkable entrepreneurs, Eli Dagan and Yehuda Yuval. Since then, they’ve grown to 115 employees across four continents. As we’ve gotten to know the people at TopTix, we’ve been struck by how similar they are to the people at SeatGeek – bright, humble, and driven by a core belief in the transformative power of technology. We couldn’t be more stoked that this extraordinary group is now part of our team.
TopTix’s primary ticketing platform, called SRO, is by far the strongest and most modern backend ticketing platform on earth. It serves more than 500 venues, and processes over 80 million tickets a year in 16 countries across the globe. Current TopTix clients range from museums and theaters to festivals and sports teams, including well-known organizations such as the Ravinia Festival, the Royal Dutch Football Association, West End theaters, and several English Premier League clubs.
We’re excited to continue to support all current TopTix clients from TopTix’s seven global offices. The TopTix engineering team will remain 100% focused on SRO, working to further extend the platform with all of SeatGeek’s resources now behind them.
We believe the future of ticketing is open. Openness means enabling teams and venues to fill their venues. Most importantly, it means making fans happier.
Joining forces with TopTix will allow us to make SeatGeek Open an even more powerful platform and to create more great experiences for fans. SeatGeek and TopTix have already helped Sporting Kansas City, our first client, sell more tickets and reach new fans, while giving supporters easy access to the games they love. Now that we’re officially operating as one, we’re feverishly excited about the potential this unlocks and our future together as a single united company.
This post is the second of a two-part series on using Vault in production. Both posts are slightly redacted forms of internal documentation. This post covers day-to-day usage of Vault, while the previous post covered our specific workflow.
Please note that some of the referenced tooling is not currently publicly available.
Not all of our practices will apply to your situation, and there are cases certainly where our setup may be suboptimal for your environment.
Using Vault
This is the tl;dr you were looking for…
For Developers
Developers should expect credentials to live in environment variables that can be loaded into an app when needed. These credential names are specified within an app.json manifest file, and Ops should be contacted to place their values in Vault. The deploy process currently uses the vault api to retrieve appropriate credentials for a service, transparent to the development staff.
The basic flow for reading or writing credentials is the following:
Login to Vault and receive a token
Make a request with the token to read or write
Schema
Secrets accordingly to the following convention:
1
secret/ENVIRONMENT/APP/KEY value=VALUE
Login
Note: Developer Vault logins require a Github Access Token (https://github.com/blog/1509-personal-api-tokens)
vault init is used to bootstrap a new Vault cluster. This generates a number of keys and requires a majority threshold of these keys in order to unseal Vault (more on unsealing below).
For SeatGeek’s Vault cluster, vault init has been run as follows:
Note: Local public key files can also submitted for the pgp-keys option
Initializing Vault this way leverages its support for authorizing users to be able to unseal Vault via their private GPG keys. This method was chosen as we already using blackbox to encrypt secrets within certain repositories.
When vault is initialized, an unseal tokens are printed out for each pgp key specified. The order of these keys matches the order in which the pgp keys were specified, and each can only be decrypted by the corresponding pgp key. Those unseal tokens should be securely distributed to the corresponding operations engineer and stored in a secure fashion. Loss of keys exceeding the threshold will result in a loss of ability to unseal the cluster.
Vault should only need to be reinitialized if all of the data in lost, which for SeatGeek would be in a loss of the Consul Cluster.
Unsealing
Vault boots up in a sealed state, and in this state no requests are answered. Each machine within a Vault cluster can be in a sealed or active state, and all must be unsealed before answering any requests. There is also a standby state, in which the machine is unsealed but not primary, and is ready for failover if the currently active primary dies.
A Vault machine can be unsealed via the following command:
The VAULT_UNSEAL_KEY is specific to each user who was specified in the vault init command. All unseal keys were distributed at the time of initialization.
Note: This requires having the vault binary installed locally.
Root Token
An initial root token is created when the Vault Cluster is initialized. Other root tokens are created from this token, and as such, if a root token is needed it must be created by an existing holder of a root token.
A new root token can be created from an existing root token via the following command:
Note: You must be logged in with a root token in order to run this command
In the emergency case that a new root token needs to be created, the following command can be run:
1
vault generate-root
This operation requires a majority of unseal key holders to execute.
Note: At this time of writing, Vault 0.6.2 has deprecated this workflow surrounding root tokens and our usage is subject to change in the future.
Provisiong a New Service
When provisioning a new service, secrets can simply be written to the appropriate bucket (secret/ENVIRONMENT/APP_NAME/KEY value=VALUE). Everything under secret/ is a “key” and all necessary paths will be created.
Whitelisting a New Service
On first boot of infrastructure, the Jenkins Whitelist deploy job, a dependency of the Jenkins Configure job, will be run. If not already, the new application will be created and its corresponding IAM Role will be whitelisted. This job also ensures all other IAM Role whitelists are up to date in Vault.
To ensure that Jenkins has the correct permissions, a special role allowing it access to write auth and policy documents should be written to Vault. The following can be used to create the policy, which is stored with all other custom vault policies:
Policies must be audited on a regular basis, consistent with all other internal auditing processes.
When used in contexts that do not easily support passing roles, you can create a vault token for this or any policy. The following creates a renewable token that is valid for 60 seconds:
The vault rekey command allows for the recreation of unseal keys as well as changing the number of key shares and key threshold. This is useful for adding or removing Vault admins.
The vault rotate command is used to change the encryption key used by Vault. This does not require anything other than a root token. Vault will continue to stay online and responsive during a rotate operation.
Disaster Response
In the case of an emergency, Vault should be sealed immediately via:
1
vault seal
This will prevent any actions or requests to be performed against the Vault server, and gives time to investigate the cause of the issue and an appropriate solution.
A secret stored in Vault is leaked
A new secret should be generated and replaced in Vault, with a key rotation following.
Vault user credentials are leaked
The user credentials should be revoked and a key rotation should be performed.
Vault unseal keys are leaked
A rekey should be performed.
A common task when working in server infrastructure is to take inventory of what is available.
This can be useful for figuring out what is out of date, when certain pieces were introduced to
your environment, or even taking stock of what items might be hidden that you otherwise were
not aware of.
For AWS users, there are a dozen ways to inspect your infrastructure:
Early on in SeatGeek’s history, we relied heavily on the AWS API to figure out what ec2
instances were available in our infrastructure for the purposes of service discovery. As we
grew in both traffic and footprint, this became unwieldy, and suffered from rate-limiting
issues, retry bugs, and general auth errors across the various utilities that interacted
with the AWS API. Thus was born haldane, a friendly http interface to the AWS API.
SeatGeek uses haldane to expose a simple http interface to the AWS API which can be
easily integrated into our toolchain. Here is an example haldane query:
The following are a few of the resources exposed via haldane:
/amis: Corresponding to AWS EC2 AMIs
/instances: Corresponding to AWS EC2 Instances
/instance-types: Corresponding to available AWS EC2 Instance Types
/rds-instances: Corresponding to AWS RDS Instances
Under the hood, haldane queries the AWS API using Boto3, and caches the resultset in memory
for a configurable amount of time. This ensures relatively fresh data from AWS, while reducing
the probability of hitting the AWS rate-limit.
In the time since we initially developed haldane, SeatGeek has seen explosive growth, and
it is no longer a solution we can depend upon for server discovery at scale. That said, it can
be very useful for any of the following use-cases:
Static infrastructure
Generating CSV reports
Querying for outdated resources
Inspecting the state of small clusters
Retrieving the IP address of a random instance in a cluster
Internally, we’ve built a few such tools to support infrastructure spelunking, and while we
may not rely on it as heavily as we used to, we hope that others can find utility in using haldane.
You can find haldane on Github, under the BSD 3-Clause License.











{kind=link}
{kind=link}