In this article we’ll explore a pattern we used at SeatGeek to improve performance and resilience for our feature-flags service implementation and to reduce the amount of code needed on each application by externalizing the retrying, caching, and persisting responsibilities to another process. We decided to describe this pattern as we feel like it has several interesting use cases for runtime application configuration.
Runtime Configuration Management
A typical pattern for distributed applications is to externalize configuration into a centralized service other applications can pull data from. This pattern was termed the External Configuration Store pattern which can be summarized as follows
Move configuration information out of the application deployment package to
a centralized location. This can provide opportunities for easier management
and control of configuration data, and for sharing configuration data across
applications and application instances.
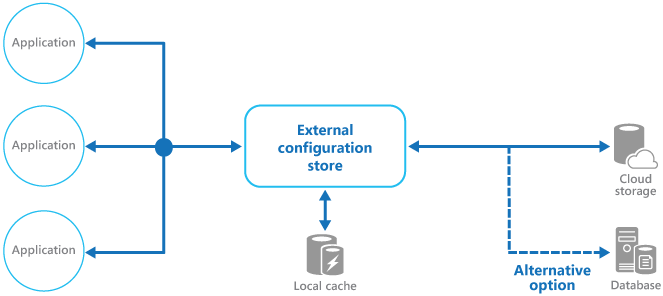
External Configuration in a Microservices world
One of the challenges of the external Configuration Store Pattern, when using for distributed applications using microservices, is the selection of the delivery mechanism. While the pattern page suggests using a backing store with acceptable performance, high availability and that can be backed up; it does not make any suggestions as to what that store might be and makes no reference at how applications can pull the configuration data at runtime.
A typical setup is to use HTTP as the delivery mechanism for the configuration data. Applications periodically poll the configuration store and optionally keep a local read cache to speed up reads in between requests. This is, for example, how the Envoy Proxy pulls configuration data from an external store to discover hosts it needs to route requests to:

Each proxy instance connects to one of the highly available configuration store servers and pulls the latest configuration data periodically. Even though this is a redundant and highly available setup, each envoy proxy instance still needs to deal with servers going away, timeouts, retries and the occasional slow response due to network latency. The configuration store also needs to be provisioned according to how many instances of Envoy proxy servers are pulling data and how frequently the data needs to be refreshed.
While all of those are known challenges and can be technically solved, the operational cost of running an external configuration store can be significant, especially if the data they serve is part of any critical code path.
When delivering configuration data over HTTP or similar transports such as gRPc or S3 to multiple applications written in different languages, we find an additional problem. Each application is responsible for implementing the retry, timeouts and caching strategies, with the almost inevitable outcome that the strategies eventually diverge.
The duplicated efforts and diverging implementations can also lead to increased costs and hidden bugs. For instance, let’s evaluate an open-source software for delivering feature toggles.
The Unleash HTTP server is a product implementing the external configuration store pattern, it serves feature toggles over an HTTP API that clients can consume locally.

Unleash offers many official client implementations, mostly contributed by the community. Some of them periodically poll the API server, and some others use a read-through cache. Since it is easy to forget that networking errors are expected in distributed applications, most of those clients implement no retry strategies, potentially leaving applications with no configuration data.
While those problems can be attributed to programming errors that can be solved by making the clients more robust, the point remains that the external configuration store pattern presents the potential for diverging implementations in the same system and duplicated efforts.
Distributing Configuration Data over SQL
A technology that is pervasive among both old and modern applications, that has had decades of tuning and has robust clients for all languages used in the industry, is a Relational Database. Such characteristics make relational databases great candidates for storing, querying and delivering configuration data changes.
Querying relational databases is common knowledge for the majority of teams, and so are the techniques for making databases highly available, and dealing with errors. Many languages offer libraries implementing best practices for accessing data in relational databases in a safe and resilient way.
We can make an addition to the External Configuration Store pattern to expressly suggest delivering the configuration data via a relational database. The rest of the pattern remains the same, just that we add an extra piece to the architecture which copies the configuration data from the centralized store into many distributed applications.

In this pattern, we introduce a worker service that copies a representation of the current configuration data into each application database and keeps the data up to date with changes from the centralized source.
Applications read directly from their local database using standard querying tools for their languages, which significantly simplifies the access pattern for configuration data. They also benefit from not having to implement additional authentication mechanisms or store other credentials for pulling configuration data from the centralized store. Moreover, they benefit from any efforts to make the application database highly available.
Finally, one of the main advantages of this pattern is improved resiliency. Since we have now mirrored the data on each application database, the source storage can be down for any arbitrary amount of time without affecting the availability of the latest known configuration data for each application.
This is especially true for applications being restarted or deployed while there is an external configuration source outage. Given that a popular technique is to request configuration data on application startup, we can guarantee that there is workable configuration data on startup even in the face of a configuration service outage.
Example
To illustrate this pattern, I’ll present a real use case of a feature toggles external storage system that we implemented at SeatGeek. In this specific case, we opted for using SQLite databases on host machines that are shared by all containers in the same host.

We kept the centralized storage and distributed a worker service to each server instances to subscribe for changes in the source data and write the changes in a normalized SQLite database in the local file system. All containers in the same host get the location for this SQLite database mounted as a volume that they can read as a local file.
At SeatGeek, we have several services using feature-toggles to determine runtime behavior of the code. Many of those services are written in languages other than Python, our default language for new services. Thanks to SQLite having an implementation for all of the languages we use in production, reading from the feature-toggles database is just a matter of using a simple SQL query.
1 2 3 | |
Results
By storing the feature toggles in a local database, we dramatically improved the resiliency of our applications by preventing missing configuration whenever the external store was unavailable.
One particular scenario that we can now handle confidently is deploying application instances while having the feature flags down for maintenance or when it is experiencing an outage. In the past, we were caching feature flag values in Redis for a short period of time, but once the cached value expired, we had to use a fallback value whenever the feature-flags service was down.
While Unleash tries to solve this issue by locally caching the feature flag values as a JSON file, given our containerized architecture, the local cache would not be transferred to a new application instance after a new deployment. By externalizing the caching of the values using a push-model, we can remove the specialized code dealing with these cases in each application.
It also simplified the implementation of the feature flags clients, as the caching strategies and polling intervals became irrelevant due to the great performance of SQLite databases.
When to use this pattern
In addition to the reasons cited in the original pattern article, we suggest following this pattern whenever:
-
You work in an organization with multiple teams needed to pull data from a central configuration storage and you want to enforce externally availability and performance guarantees without relying on teams implementing correctly strategies for pulling the configuration data from the central storage.
-
You need near real-time configuration data changes or the rate of change of the configuration data is frequent enough that applications need to poll the storage more frequently than you can afford.
-
You have applications in distant regions of the globe and want to cheaply Implement fast access to configuration data stored in another region.
-
You wish to enable applications to search, filter or select only partial fields from your configuration data and your configuration provider does not allow such operations.
-
You would like to have the configuration data available in your database so you can use
JOINswith other tables in the system.
Conclusion
We have shown a powerful pattern that can be used to simplify runtime configuration of applications by externalizing it via a relational database. In our particular case, we used SQLite databases to implement a push-model cache, which drastically improved resilience, performance and simplicity of our feature-flags by implementing an external process to keep the databases up to date.
After implementing this pattern for our feature-flags service, we were motivated to investigate how this can be generalized for use cases beyond pure configuration data. We are now exploring ways of distributing read-only APIs through databases as a way to improve data locality and open up the possibility of doing fast joins with data coming from heterogeneous sources. A future write up about our findings coming soon!