This is part 1 of a three-part series on Checkpoint, our internal IAM automation platform. In this post, we explore the problem we faced with traditional IAM approaches and how we reframed it to build a better developer experience. In part 2, we will dive into the technical details of Checkpoint’s architecture and features. Part 3 will cover the impact it had on our teams and processes.
Access control defines how a company works. We only noticed ours when it stopped working.
At SeatGeek, we quietly hit a wall. Our company had grown past 1,200 employees. We were operating across dozens of AWS accounts. Teams shifted often. Roles were fluid. Ownership was shared. But our approach to Identity and Access Management (IAM) remained stagnant and could no longer keep up with the pace of change.
Engineers were getting blocked daily. New hires spent days waiting for the right permissions. Requesting access was unpredictable. Sometimes it went through IT. Sometimes through Slack. Other times to an endless Jira backlog and unfortunately sometimes not at all. Support teams could not reach the tools they needed. Managers had no visibility into who had access to what. The system was unclear, and it was breaking in subtle but painful ways.
“ClickOps” became the norm. Teams made manual changes in the AWS console. There were no approvals, no expiry dates, and no reliable records. Risk increased. Accountability decreased. And auditing it all was a nightmare.
We realized this was not only a Security issue, it was a broken developer experience that was impacting the entire company.
The Hidden Cost of “Getting Unblocked”
Most IAM systems rely on control and enforcement. Engineers get blocked. They file a ticket. Someone else makes a decision. Eventually, access is granted. Sometimes it is too narrow. Sometimes it is too broad. It depends on who asks, who approves, and how well they understand each other.
When we audited existing AWS access across the company, we found something startling: there were more users with AWS administrator privileges than we ever would have guessed. This was not a one-off. It was the standard.
Not because people were reckless, but because getting access was so hard. People guessed what they needed. They copied roles from teammates. They granted broad access because narrow, precise access took too long to figure out.
Onboarding was one of the clearest signs something was wrong. New engineers sometimes waited a full week to get into the tools they needed. A single missing permission could block progress. There was no visibility into what was missing or how to request updates cleanly.
When access is slow or unpredictable, people work around it. They don’t mean to be unsafe, they’re just trying to get their work done. Users ask for admin access not to gain power, but to stop being stuck.
That’s where the real risk starts. Not with a single permission, but with a culture of “lets make it work”.
The Root of the Problem
We wanted to understand the full scope of the problem so we created a feedback wall and started interviewing folks across the company about their experience getting new access. We were shocked to learn that even folks who had been at the company for 5+ years were still struggling with the process. How could a newcomer expect to get access quickly when even veterans were confused?
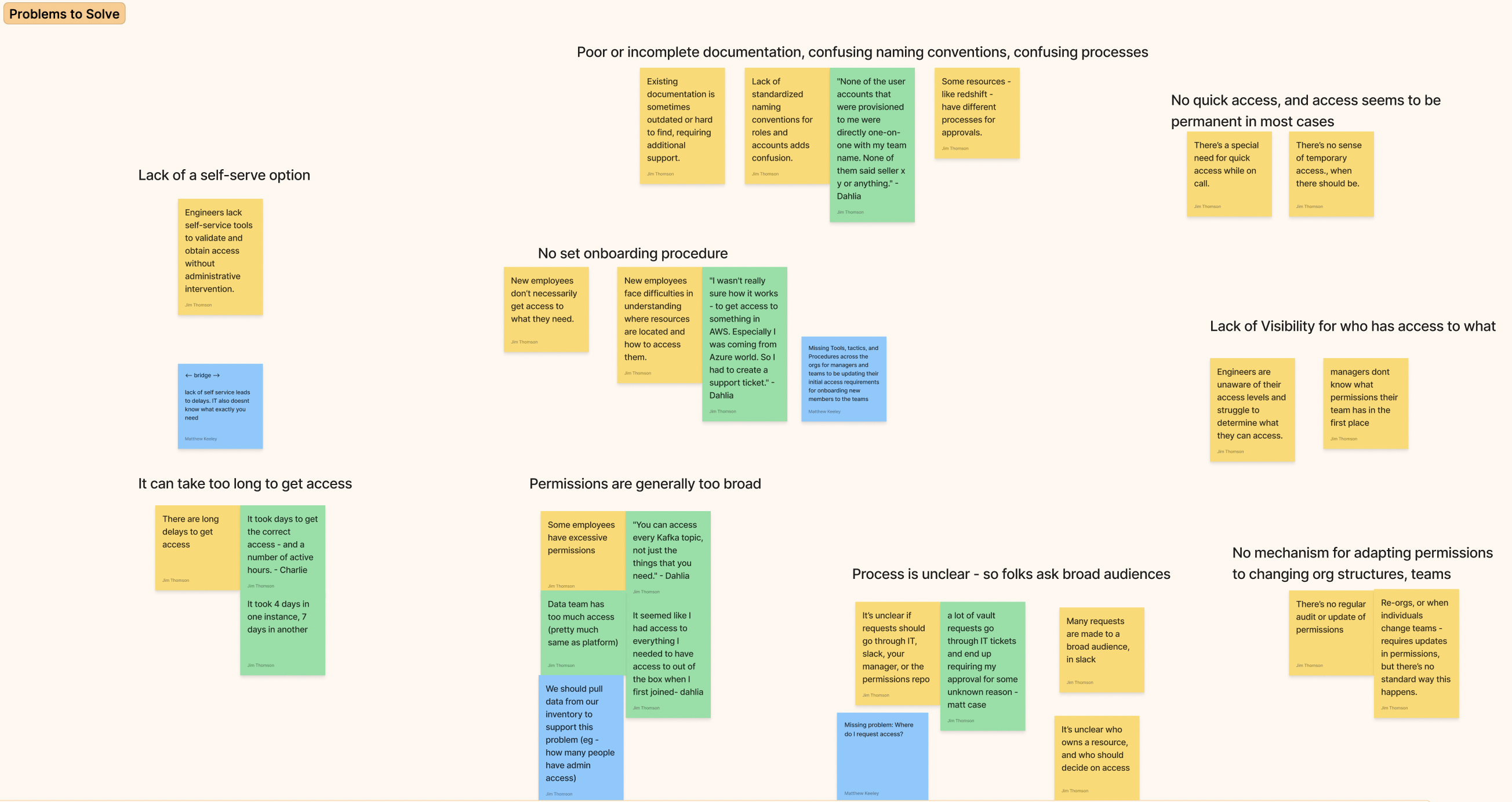
The responses came quickly:
It took four days in one instance, seven days in another, just to get the correct access.
I had to create a support ticket to reach an AWS account. I was coming from Azure and had no idea where anything was.
There is no clear way to request access. Sometimes it goes through IT, sometimes Slack, sometimes it’s a mystery.
As a manager I can’t even tell what my team members have access to.
I had full production access, I wasn’t even sure why.
The themes were consistent, IAM had finally stopped being invisible and became a real source of friction.
Checkpoint: Designing for Experience, Not Enforcement
What if IAM worked like a developer facing product with a delightful experience? Not something hidden in the background, but something people could see, use, and trust.
We decided to build a system for fixing our biggest problems, introducing Checkpoint!
The wall of sticky notes became our blueprint. We no longer wanted to patch the old model, instead we set out to rebuild it into something that supported engineers rather than slowed them down.
Principles of Checkpoint
These principles combine our design philosophy and must-have requirements. They guided every decision we made.
Principle 1: Make the Secure Path the Easiest Path
Developers gravitate towards the easiest way to get their work done. If the secure path has too much friction, they will find a workaround even if they know it is unsafe. Checkpoint is embedded directly in Slack so it meets people where they already work, with an experience that is fast, self-service, and easy to understand.
Principle 2: Just in Time, Not Just in Case
Most tasks need hours of access, not weeks. Traditional IAM access is permanent and assigned at the team level, creating long-term exposure. In Checkpoint, access is temporary by default, automatically removed when it expires, and easy to renew if necessary.
Principle 3: Self-Service by Default
No one likes waiting for access. Anyone in the company can request permissions without the Platform or Security teams constantly gatekeeping. Low-risk requests are auto-approved, medium-risk requests go to the service owner, and high-risk requests escalate to Security. This keeps the Platform team out of the critical path while still maintaining oversight.
Principle 4: Services are durable, teams are fungible
Permissions are tied to durable microservices instead of short-lived internal teams. We bundle all access for a service once and reuse it for anyone who needs it. This scales across teams and accounts while reducing repetitive policy management.
Principle 5: Break Silos, Respect Boundaries
Owning teams define bundles, lifespan, and approval rules, not the Platform team. Checkpoint is auditable and compliant by design, while still allowing engineers to request scoped, temporary access without escalation. This enables faster cross-team collaboration while respecting service owner boundaries.
Coming Up Next
In Part Two, we’ll explore how Checkpoint works under the hood. From Slack workflows and just-in-time access to permission bundles and incident response, we’ll show how we built a system that is fast, safe, and scalable across every department.
We’ll share what we learned after Checkpoint launched, and how we are iterating to make it better!
Spoiler:
- Access requests now complete in seconds
- Persistent admin access dropped to zero
- Everyone from engineering to finance uses it on a daily basis
But first, we had to reframe the problem. To make it real, we connected Okta for identity, AWS permission sets for per-user access, and simple interfaces like a website and a slackbot that handles approvals where our customers already work. In Part Two, we will show how we bundled permissions around the services themselves, built a risk classification model to automatically approve low risk requests instantly, and routed higher risk requests directly to the service owners who know their products best so that approvals are fast, distributed, and safe.