At SeatGeek, we are obsessed with delivering a fast, reliable, and scalable ticketing experience. Our platform handles millions of users searching, interacting with listings, and making purchases every day, so it must be resilient, particularly during extreme traffic spikes. This post will cover our resilience strategy, including how we utilize Fastly for CDN caching and shielding, how Kong API Gateway rate limits protect our upstream services, and how we validate this strategy with k6 load tests.
CDN Caching with Fastly: More Than Just the Edge
Caching is one of the most effective ways to improve performance and scalability. By serving responses from the edge instead of going all the way to our infrastructure, we reduce latency, save compute cycles, and increase reliability.
Shielding Explained
Fastly’s caching architecture is hierarchical. When a user makes a request, it hits the closest Point of Presence (POP). If the response is not already cached there, Fastly does not immediately reach upstream; it first checks a shield POP.
Think of the shield POP as a designated regional cache layer between the edge and your origin. We configure a specific POP (e.g., IAD in Ashburn) to act as the shield for all other POPs. Here is how it works:
- User Request → Hits local POP (e.g., LHR in London).
- Cache Miss → Instead of contacting our backend, LHR POP forwards the request to the shield POP (IAD).
- Shield POP Check:
- If IAD has the response, it sends it back to LHR.
- If it does not, IAD fetches it from the origin, caches it, and then returns it to LHR.
This response is then cached both at the shield POP (IAD) and the original edge POP (LHR), reducing future latency and origin load.
One key advantage of shielding is that it reduces origin traffic and protects your infrastructure from redundant requests. Even if multiple edge POPs experience simultaneous cache misses, only the shield POP will contact the origin.
Another significant benefit is that traffic between POPs, including between the edge and the shield, is routed over Fastly’s private backbone, rather than the public internet. This backbone is optimized for speed and reliability, offering lower latency and consistent regional performance.
Cache Policy
To maximize efficiency, we define cache policies based on content volatility and sensitivity. Our current strategy includes:
- Static assets (images, CSS, JS): These utilize a long Time-To-Live (TTL) and do not require revalidation.
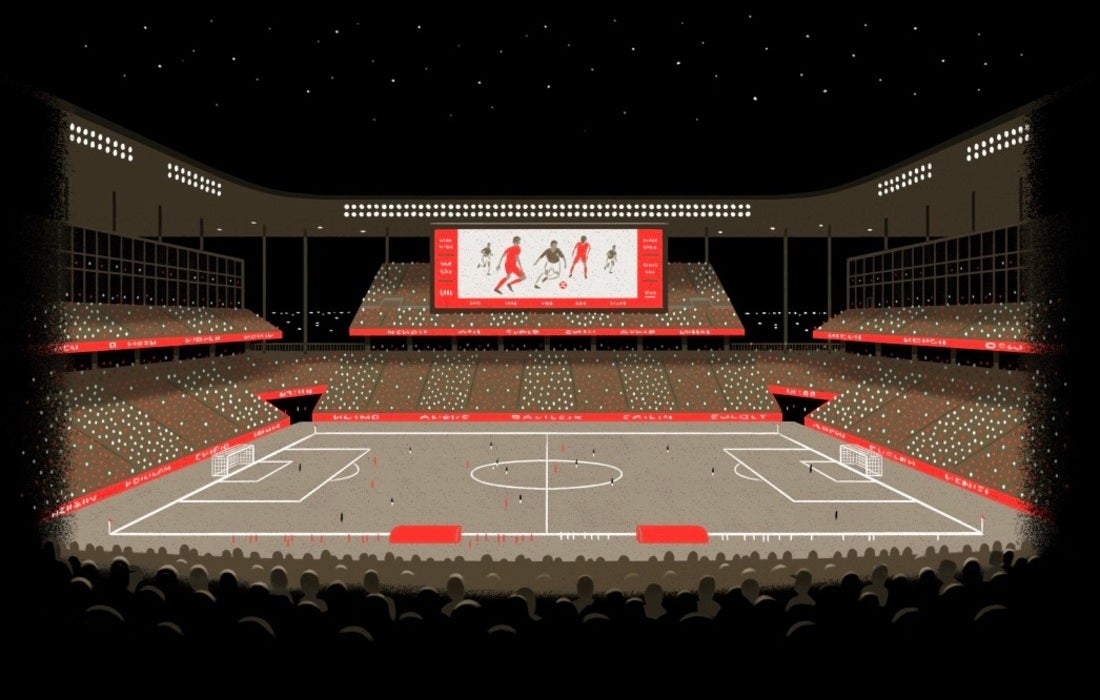

- Dynamic content with stable responses (e.g., images of individual rows in an arena): These are assigned a short TTL and employ a stale-while-revalidate strategy for optimal balance.
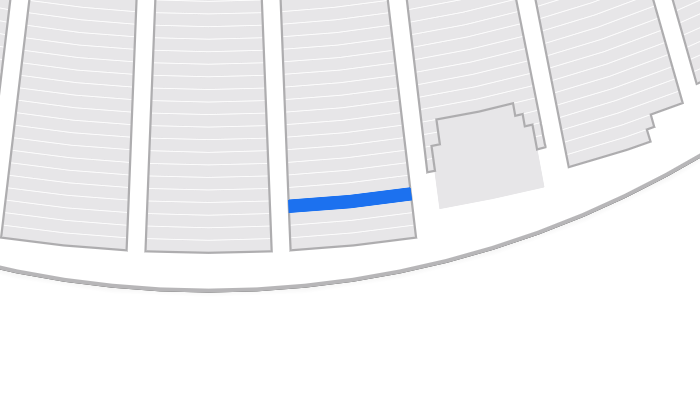
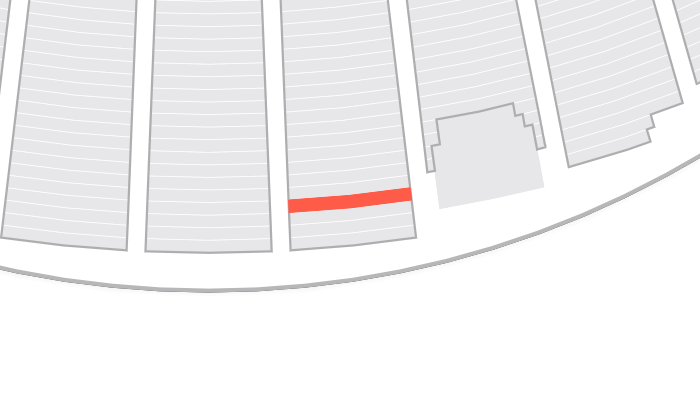
- API responses with cacheable payloads: These are selectively cached using surrogate keys and Fastly’s custom VCL.
Soft purging is also employed to update data, ensuring cache continuity. We leverage Fastly’s capabilities to cache content based on headers, query parameters, and cookies (though the latter is used with caution).
Protecting Upstream Systems with Rate-Limiting
Caching is powerful, but only if your origin services stay healthy. A service that fails under pressure is one of the biggest threats to cache efficiency. In most cases, failed responses (non-2XX) are not cached, which leads to a dangerous feedback loop:
- More failures → fewer cacheable responses.
- Fewer cache hits → more origin traffic.
- More traffic → more failures.
Here is what that feedback loop looks like in practice:
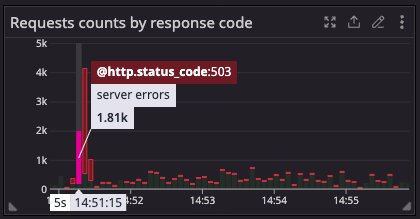
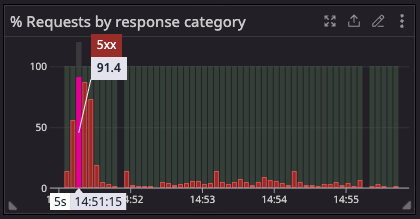
At SeatGeek, this pattern emerges with services like venue maps. When demand surges, for example during a high-profile onsale, if the venue maps service starts to fail, those failed responses are not cached. As a result, every new user request bypasses the cache and hits the already-overloaded service again. The result is a degraded experience: users cannot view the venue layout to choose their preferred section, increasing frustration and potentially hurting conversion during a critical moment in the purchase journey.
This is where rate limiting becomes essential, and where the API Gateway plays a critical role in the architecture. As the Ingress point for public traffic, the Gateway (in our case, Kong) sits between Fastly and our backend services. It acts as a safeguard, enforcing traffic policies and rate limits to protect sensitive systems.
The request flow diagram below illustrates this layered architecture—from the edge POP to the shield POP, through Kong, and finally to the origin. Each component plays a role in preserving service health and maximizing cache efficiency.
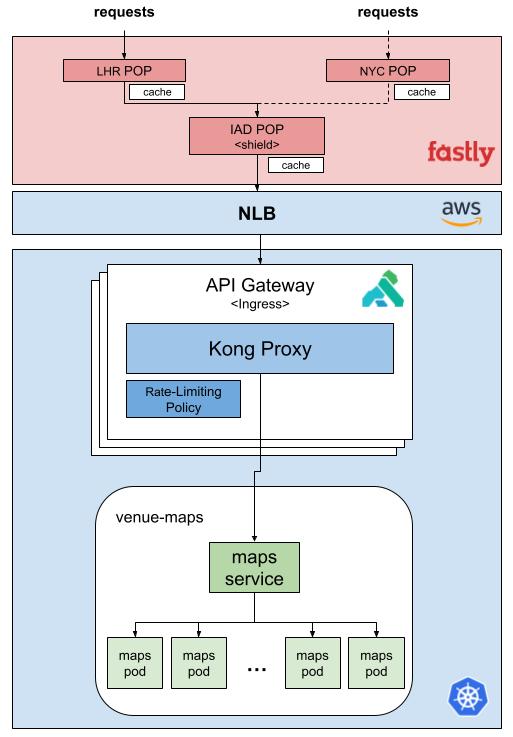
Kong API Gateway in Action
We use Kong as our API Gateway to handle ingress traffic. Kong allows us to define rate-limiting policies per service or route, protecting sensitive APIs and stabilizing behavior under load.
We typically apply:
- Token bucket rate limits for general APIs.
- Per-consumer limits for apps, bots, and partners.
- Circuit-breaking thresholds for vulnerable services.
Kong acts as a gatekeeper: when requests exceed the configured thresholds, they are throttled (e.g., returning 429 responses). This helps ensure upstream systems stay responsive for legitimate, sustainable traffic.
The result? More successful 2XX responses, which are cacheable, improve the cache hit ratio and reduce load on the origin. The cache naturally warms up as the system remains healthy, and rate limiting prevents overload.
Observing the Effect
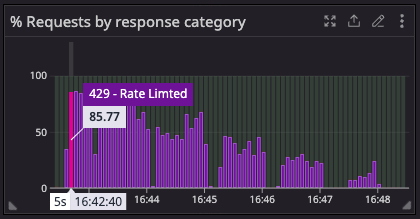
Graph 1 illustrates a high initial percentage of 429 errors during a traffic surge, indicating that Kong’s rate-limiting effectively shielded the upstream system from excessive load. The subsequent decline in 429s shows system stabilization as clients adjusted or backed off.
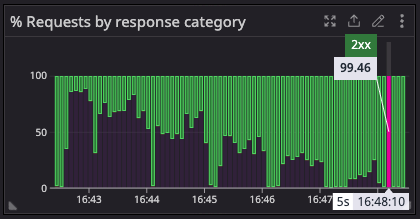
Graph 2 presents an inverse pattern: the percentage of 200 responses begins low but progressively rises. This trend signifies enhanced efficiency due to cache warming, rather than recovery from a failure. As rate limiting manages the load and upstream responses stabilize, more requests are served from the cache. This reduces the need to access the upstream, leading to a greater proportion of successful, fast, and cacheable 200 responses.
Graph 3 demonstrates the cache hit rate, a key indicator of this shift. As the cache populates, the hit rate increases, diminishing upstream dependency, enhancing latency, and elevating the success rate seen in Graph 2.
Load Testing with k6: Validating Cache Behavior Under Pressure
We use k6 to test our caching and rate-limiting strategies under realistic conditions. While synthetic benchmarks have their place, we prefer tests that replay production-like traffic in staging environments.
Simulating Real Requests
We simulate real production-like traffic patterns using this approach:
- Capture a pool of production requests (method, path, headers, etc.).
- Sanitize production requests to ensure we are not moving sensitive data between environments.
- Add a randomized cacheBuster query param to each request to force an initial miss.
- e.g., /events/123?cacheBuster=abc123
- Replay the traffic using k6 at a controlled RPS (Requests Per Second).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 | |
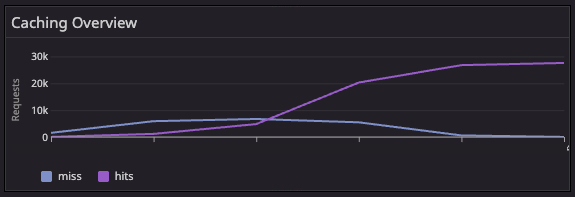
Each request has a unique cacheBuster query parameter appended to it to force a cache miss on the first run. This simulates a cold cache scenario where the CDN must fetch responses from the origin. As the system returns successful 2XX responses, Fastly’s shield POPs begin caching them, followed by the edge POPs. Over time, this leads to fewer origin requests and a higher cache hit ratio.
By using SharedArray, the CSV is loaded and transformed once during test initialization, ensuring efficient memory usage across virtual users. This setup allows us to simulate realistic traffic patterns and observe the system’s behavior under load:
- The initial origin load is high (all cache misses).
- Shield POPs begin caching.
- Origin traffic decreases over time.
- The cache hit ratio rises.
- System stays within limits; no failure cascades.
It also gives us the ability to validate key behaviors:
- Cache fill timeline and efficiency.
- Kong’s rate-limiting performance in protecting upstream services.
- Overall system stability under pressure.
This method has proven particularly effective for short-lived caching of dynamic images, geo-personalized content, and non-volatile API responses.
Final Thoughts
Our caching and rate-limiting strategy is built on a simple principle: successful requests today become fast responses tomorrow. By combining Fastly’s shielding architecture with well-defined cache policies and Kong’s rate-limiting controls, we create a self-reinforcing loop that reduces load, improves reliability, and scales with demand.
One of the key benefits of this approach is that the cache naturally warms up over time. Rate limiting plays a critical role here: by protecting the system from overload, it ensures a steady stream of successful responses that can be cached and distributed across Fastly’s edge and shield POPs. The more the system stays within safe limits, the faster and more cache-efficient it becomes.
This is not just about infrastructure efficiency, it directly impacts the fan experience. During high-traffic moments, rate limiting helps avoid slowdowns, errors, or degraded service. Instead of risking outages or broken flows, we ensure that as many fans as possible receive fast, reliable access. In that sense, it is a strategy designed not just for system health, but to deliver the best possible experience at scale.
By contrast, when a system fails under load, the impact is immediate and compounding: fans experience delays or errors, and the missed opportunity to populate the cache puts further pressure on downstream systems. Resilience is not just about surviving a spike; it is about staying healthy long enough to let the cache take over.
We validate this entire approach through load testing with k6, ensuring we are not just hoping our systems perform under pressure — we are proving it, under production-like conditions.
At SeatGeek, we are redefining live event engagement through innovative technology, personalized services, and a fan-first mindset. From discovery to post-event, we aim to create seamless, memorable, and immersive experiences for every attendee.