Two years ago we wrote Refactoring Python with LibCST which documented SeatGeek’s first foray into building custom codemods to automate large-scale refactors of our codebases. We used the then-new LibCST library from Instagram to modernize thousands of lines of code in our consumer-facing Python applications.
This post details our newest venture: building custom codemods to automate large-scale refactors of our Go codebases. Go powers most of our Platform Engineering services, as well as some critical consumer-facing applications. We’ll discuss:
- Why we wrote a Go codemod
- How we used go/analysis to write our codemod
go/analysis: The Good, the Bad and the Ugly
(If you’re interested in the codemod itself, you can explore the source code at https://github.com/seatgeek/sgmods-go.)
Why we wrote a Go codemod
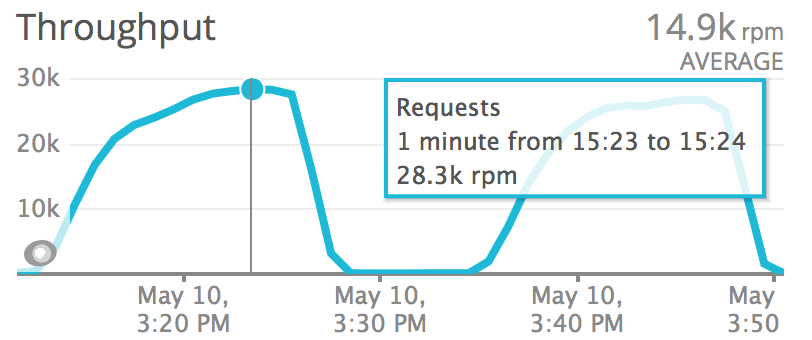
We recently shipped a new edge service at SeatGeek that allows us to better handle high-throughput events (like ticket onsales) without overloading our core infrastructure. The service is written in Go, is deployed to lambda + our CDN, and is dependent on several external services, like DynamoDB, Fastly and TimestreamDB.
We communicate with these services using their Go SDKs. When a call to a service fails, we “swap out” the error returned by the SDK with an internally-defined error that can be understood elsewhere in our application. Here is an example of what this might look like:
1 2 3 4 5 6 7 8 9 | |
In a Python application, we could use Python’s exception chaining to propogate our own error (ErrDynamoDBGetItem) while preserving the data attached to the error returned by the DynamoDB SDK’s .GetItem(). But this is Go! Our errors are not so smart. If this code were running in production, we may suddenly see a burst of errors with the message "error getting item from dynamodb table" in our observability platform, but we wouldn’t know what caused that error, because any message attached to err has been lost. Is DynamoDB temporarily down? Is our DynamoDB table underprovisioned and timing out? Did we send an invalid query to DynamoDB? All of that context is lost when we replace err with ErrDynamoDBGetItem.
Go’s solution to this problem is “error wrapping.” We can return our own error, but Wrap it with the message returned from the DynamoDB SDK, like such:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
The change is fairly simple, and given this is a newer codebase, performing this refactor by hand wouldn’t be too difficult. The value of automating this refactor as a codemod is that we can ensure all code written in our application moving forward follows this new pattern and do so with minimal developer friction. If a developer pushes code that introduces an unwrapped error, we can catch it with our linter and flag it in CI. We can then use our codemod to update our code to make it production-ready.
How we used go/analysis to write our codemod
If you’re looking for a full guide on writing a Go codemod, we recommend the article Using go/analysis to write a custom linter (which we followed in writing our codemod) and the official go/analysis docs. This section will delve into how we applied the go/analysis toolset to our refactor, but won’t give a complete tutorial on how to use the underlying tools.
The refactor
We’ve found it helpful when writing codemods to have a working mental model of our refactor before putting anything into code. Let’s start with the example we shared before:
1 2 3 4 5 6 7 8 9 | |
If we try to put our desired refactor into words, we can say:
- When we see an if block
if err != nil {, we want to look through the statements in that if block’s body - When we find a return statement inside an
if err != nil {, check if we’re returning an internal error type- All of our errors follow the Go convention of having the
Err.*prefix, so this is a string comparison
- All of our errors follow the Go convention of having the
- Update that return value to
errors.Wrap({ORIGINAL_RETURN_VALUE}, err.Error()) - After parsing a file, if we’ve introduced any error wrapping, add the
github.com/pkg/errorspackage to our imports- If the package is already imported, we can rely on our go formatter to squash the two imports together; there’s no need to stress over this functionality within our codemod
Now that we have a working mental model for our refactor, we can start to translate our refactor into the Go AST. An AST, or abstract syntax tree, is a tree representation of source code; most codemod tooling (that isn’t pure text search & replace) works by parsing source code, traversing and updating its AST, and then re-rendering the AST back to the file as source code.
Let’s look at our if err != nil {} expression to see how it would be represented in the Go AST. A quick text search in the Go AST docs for “if” finds the IfStmt struct. For now, we’re only concerned about the case where our if statement’s condition is (exactly) err != nil. (Once we’ve built out enough code to support this base case, we can iteratively add support for edge cases, for example, something like: err != nil && !config.SuppressErrors.) After some more time grokking the go/ast docs, it seems this is the node we’re looking for:
1 2 3 4 5 6 7 8 9 10 11 12 | |
Using go/analysis
go/ast provides the primitives needed for understanding Go source code as an AST, as we’ve just seen. go/analysis, on the other hand, provides the toolset used for traversing/modifying that tree, emitting messages to users, and generating CLIs for our codemod.
The primary type in the go/analysis API is the Analyzer. To define our error wrapping codemod, we create a new instance of the Analyzer struct, defining its name, user docs, dependencies and Run function - which will encapsulate our codemod logic.
1 2 3 4 5 6 7 8 | |
Analyzer.Run houses our business logic and provides a low-level API for interacting with our parsed source code. The inspect.Analyzer dependency, which we require in WrapErrorAnalyzer.Requires, provides a more familiar interface for traversing our AST: a depth-first traversal of our AST nodes.
When we call inspector.Nodes within Run, we walk each node of our AST (that is: every function, variable assignment, switch statement, and so on in our program). Nodes are “visited” twice, once when “pushing” downward in our depth-first search (this is the “visit” action) and once when we are returning back up our tree (this is the “leave” action). At any point we can use the pass parameter from Analyzer.Run to emit messages to the user or introduce code modification to the AST. We can also update local analyzer state, which we use in this case to remember whether or not we’ve introduced the errors.Wrap function when visiting an ast.IfStmt and therefore need to add the “errors” import when we leave our ast.File.
Check out the source code of WrapErrorAnalyzer to see how all of this looks in action.
go/analysis: The Good, the Bad, and the Ugly
The Good
go/analysis provides great tools for using and testing your analyzer. The singlechecker and multichecker packages allow you to create a CLI for any analysis.Analyzer with only a few lines of boilerplate code. Check out our main.go file.
The analysistest package provides utilities for testing analyzers, following a similar pattern to the one we used in our LibCST codemod tests. To create a test, we write example.go, a source file to run our codemod on, and example.go.golden, what we expect our file to look like after running our codemod. analysistest will automatically run our codemod on example.go and check that the output matches example.go.golden. Check out our test files.
The bad
While analysistest provides a solid testing framework, there are some difficulties in writing the example test files. All files live in a testdata/ directory, which means that all files are part of the same go package. Any package errors will break the test suite. This means that each test example must have unique symbol names to avoid conflicts (e.g. two files in testdata/ can’t both have func main() {}). We also struggled to get imports of third-party libraries to work: we couldn’t write a test file that imports from “github.com/pkg/errors” as it broke package loading, even if “github.com/pkg/errors” is in our repo’s go.mod.
go/analysis lacks an API similar to LibCSTs matching API, which provides a declarative “way of asking whether a particular LibCST node and its children match a particular shape.” We’ve found that the matching API makes codemod code more accessible and reduces complexity of long, imperative functions to check if a node matches a given shape. For an example of how a matching API could improve our Go codemod, let’s look at our ifErrNeqNil function, which returns true if an IfStmt in our AST is an if err != nil{}.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
This function works, but it’s a bit noisy (we need a go typecast for each side of the BinaryExpr). It also doesn’t lend itself well to evolution. What if we want to check for the binary expression nil != err? The size of our return statement doubles. What if we want to check for the case where our if statement condition chains multiple binary expressions, like: !config.SuppressErrors && err != nil? Our imperative function will become more complex and less clear in what it is checking.
If we imagine a golang matcher API, on the other hand, we can compose together declarative shapes of how we expect our AST to look, rather than write imperative logic to accomplish the same goal.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 | |
All we do here is declare some shapes we want to match in our parsed source code’s AST and let the matcher package perform the work of checking if a node in our AST matches that shape.
The ugly
To edit an AST using go/analysis, you emit a SuggestedFix. The SuggestedFix is, essentially, a list of pure text replacements within character ranges of your source code. This mix of traversing source code as an AST, but editing source code as text is… awkward. Updates to nodes deeper in the AST aren’t reflected when leaving nodes higher in the tree, as the underlying AST hasn’t actually been updated. Rather, the text edits are applied in one pass after the traversal of the tree is done. A consequence of this is noted in the docs for SuggestedFix: “TextEdits for a SuggestedFix should not overlap.” This could make writing codemods for more complex refactors, in which multiple nested nodes in the same AST may need to be updated, difficult (if not impossible). That being said, the SuggestedFix API is marked as Experimental; we’re curious to see how it develops moving forward.
If you’re interested in helping us build codemods for our codebase at scale, check out our Jobs page at https://seatgeek.com/jobs. We’re hiring!